Opticks : GPU Optical Photon Simulation for Particle Physics with NVIDIA OptiX
Opticks : GPU Optical Photon Simulation for Particle Physics with NVIDIA® OptiX™
Simon C Blyth, National Taiwan University — https://bitbucket.org/simoncblyth/opticks — July 2017 IHEP
Opticks Benefits
Opticks Progress : Moving to Fully Analytic GPU Geometry
Geometry Status (Nov 2016)
- mostly approximated, using G4 tesselation
- based on G4DAE geometry export
- manually analytic PMT geometry
- partition CSG solids into single primitive parts
- splits at joins avoid general CSG boolean intersection
Geometry Status (July 2017)
- general CSG tree intersection implemented on GPU
- automated conversion, GDML -> glTF -> Opticks GPU
- currently debugging geometry (coincident faces)
[1] LLR Workshop, https://simoncblyth.bitbucket.io/env/presentation/opticks_gpu_optical_photon_simulation_nov2016_llr.html
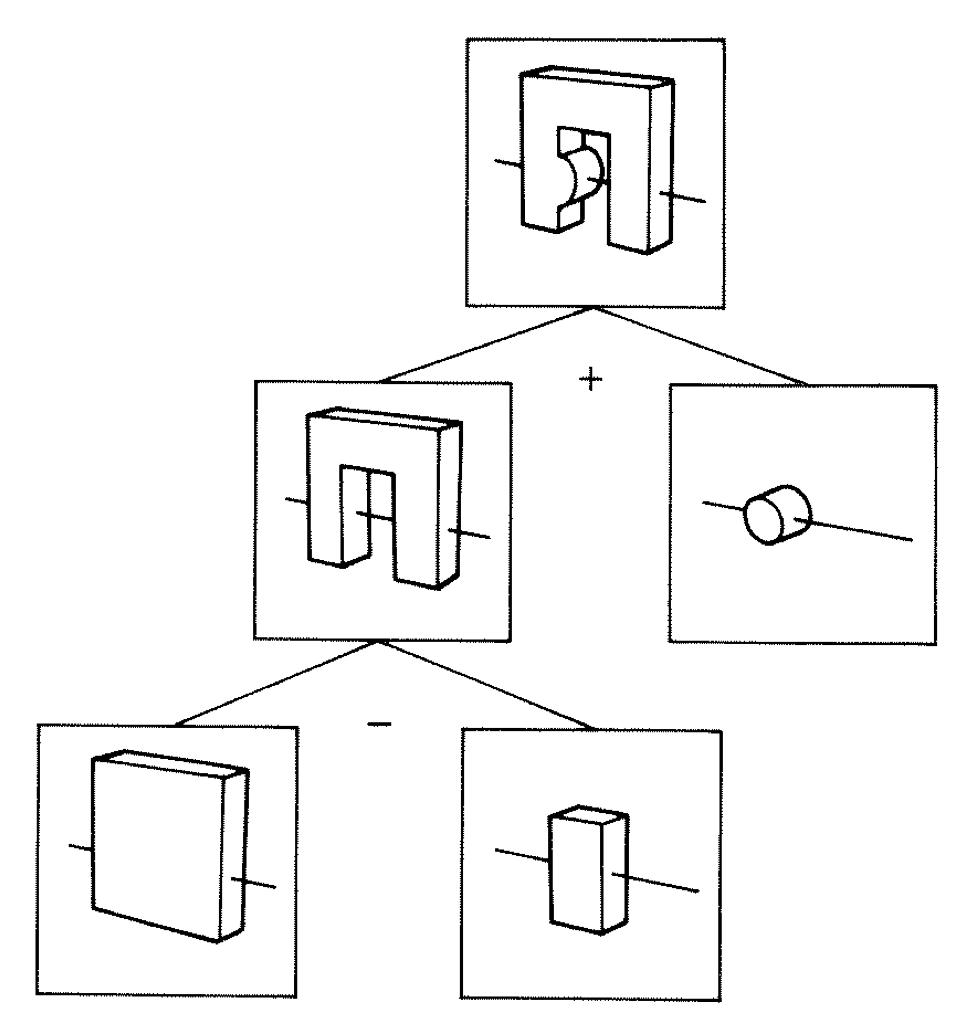
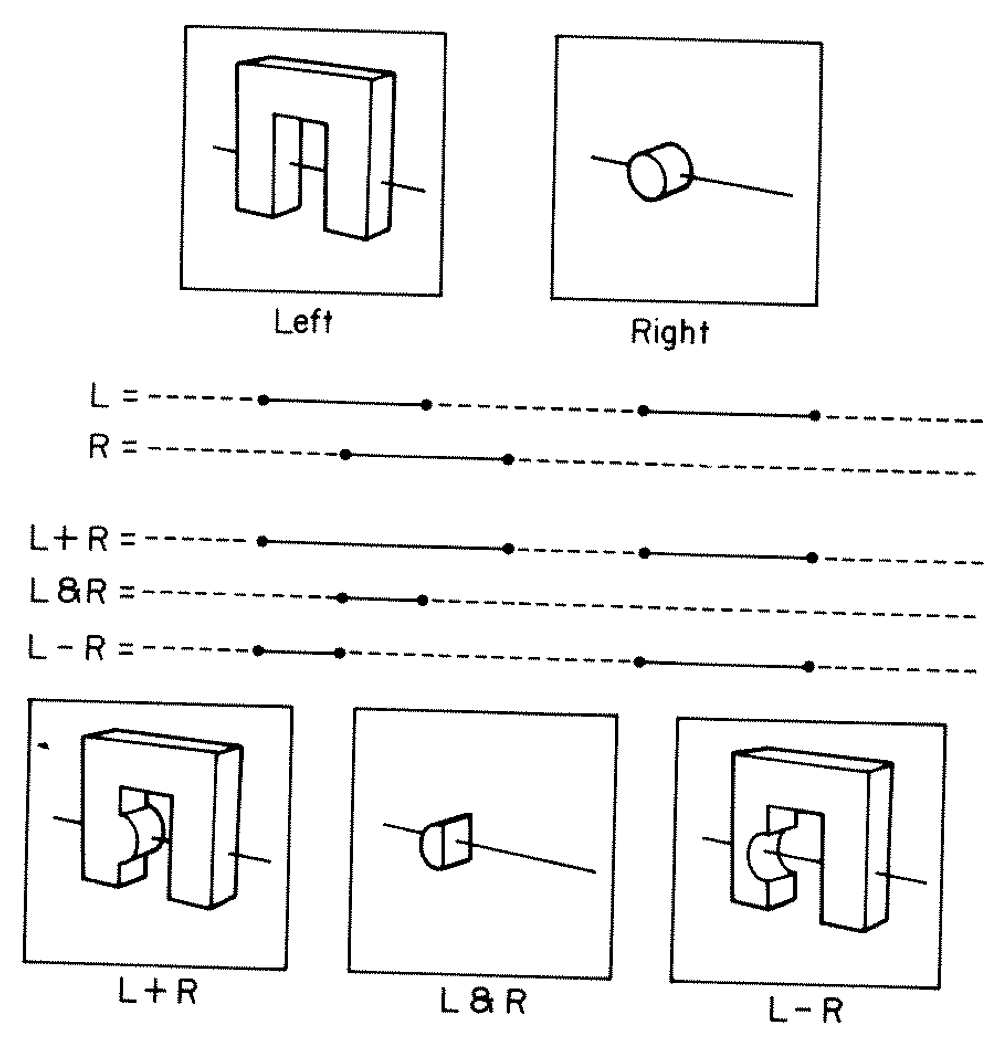
Constructive Solid Geometry (CSG)
Simple by construction definition, implicit geometry.
- A, B implicit primitive solids
- A + B : union (OR)
- A * B : intersection (AND)
- A - B : difference (AND NOT)
- !B : complement (NOT) (inside <-> outside)
CSG expressions
- non-unique: A - B == A * !B
- represented by binary tree, primitives at leaves
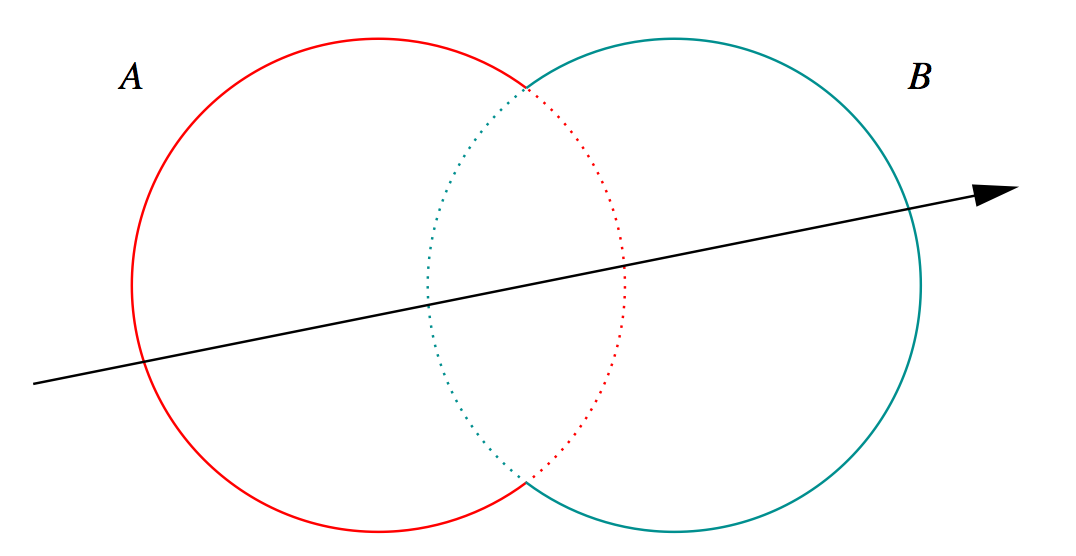
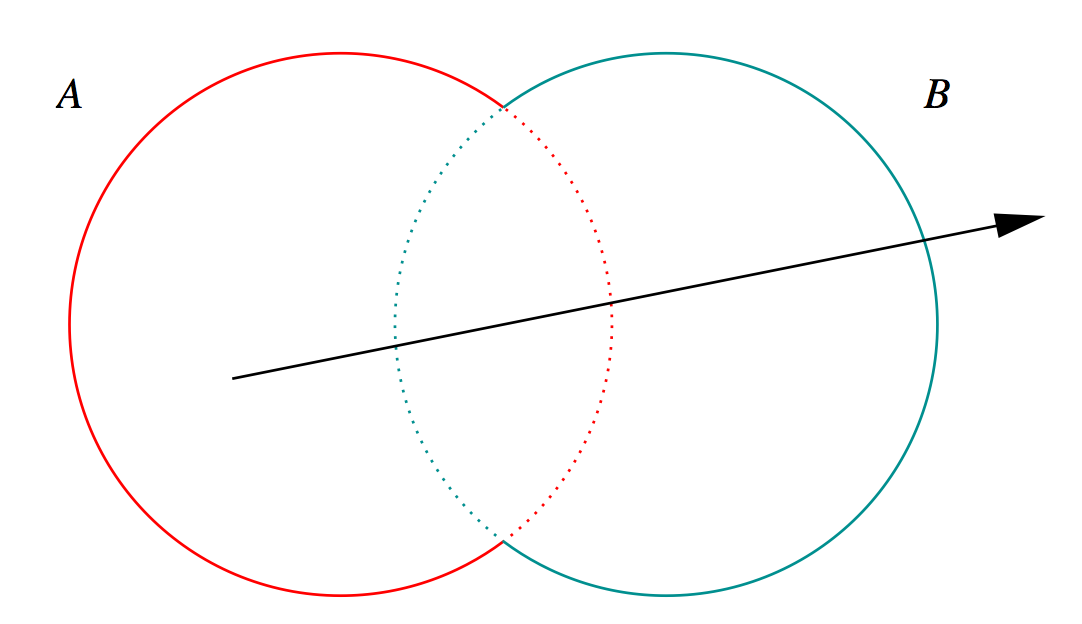
3D Parametric Ray : ray(t) = r0 + t rDir
Ray Geometry Intersection
- primitive : find t roots of implicit eqn
- composite : pick primitive intersect, depending on CSG tree
How to pick exactly ?
CSG : Which primitive intersect to pick ?
Classical Roth diagram approach
- find all ray/prim intersects
- recursively combine inside intervals using CSG operator
- works from leaves upwards
Computational requirements:
- find all intersects, store them, order them
- recursive traverse
BUT : High performance on GPU requires:
- massive parallelism -> more the merrier
- low register usage -> keep it simple
- small stack size -> avoid recursion
Classical approach not appropriate on GPU
Ray Tracing CSG Objects Using Single Hit Intersections (A. Kensler) [*]
- Classify A,B intersects, Enter/Exit/Miss
- state(A,B) -> action
- LoopA : tMinA->tA, re-intersectA, re-classifyA (ditto LoopB)
| Union, tA < tB |
Enter B |
Exit B |
Miss B |
|---|
| Enter A |
ReturnA |
LoopA |
ReturnA |
| Exit A |
ReturnA |
ReturnB |
ReturnA |
| Miss A |
ReturnB |
ReturnB |
ReturnMiss |
| Union, tB < tA |
Enter B |
Exit B |
Miss B |
|---|
| Enter A |
ReturnB |
ReturnB |
ReturnA |
| Exit A |
LoopB |
ReturnA |
ReturnA |
| Miss A |
ReturnB |
ReturnB |
ReturnMiss |
Recursive CSG tree python prototype of Kensler pseudocode worked after state table corrections/extensions
- BUT GPU/OptiX demands: no recursion in intersect program
- [*] Ray Tracing CSG Objects Using Single Hit Intersections, Andrew Kensler (2006)
- with corrections by author of XRT Raytracer http://xrt.wikidot.com/doc:csg
CSG Complete Binary Tree Serialization -> simplifies GPU side
CSG Tree, leaf node primitives, internal node operators, 4x4 transforms on any node,
serialized as complete binary tree:
- bit twiddling navigation avoids recursion
- no need to deserialize
- no child/parent pointers
- BUT: very inefficient when unbalanced
Height 3 complete binary tree with level order indices:
depth elevation
1 0 3
10 11 1 2
100 101 110 111 2 1
1000 1001 1010 1011 1100 1101 1110 1111 3 0
postorder_next(i,elevation) = i & 1 ? i >> 1 : (i << elevation) + (1 << elevation) ; // from pattern of bits
Postorder tree traverse visits all nodes, starting from leftmost, such that children
are visited prior to their parents.
Evaluative CSG intersection Pseudocode : recursion emulated
fullTree = PACK( 1 << height, 1 >> 1 ) // leftmost, parent_of_root(=0)
tranche.push(fullTree, ray.tmin)
while (!tranche.empty) // stack of begin/end indices
{
begin, end, tmin <- tranche.pop ; node <- begin ;
while( node != end ) // over tranche of postorder traversal
{
elevation = height - TREE_DEPTH(node) ;
if(is_primitive(node)){ isect <- intersect_primitive(node, tmin) ; csg.push(isect) }
else{
i_left, i_right = csg.pop, csg.pop // csg stack of intersect normals, t
l_state = CLASSIFY(i_left, ray.direction, tmin)
r_state = CLASSIFY(i_right, ray.direction, tmin)
action = LUT(operator(node), leftIsCloser)(l_state, r_state)
if( action is ReturnLeft/Right) csg.push(i_left or i_right)
else if( action is LoopLeft/Right)
{
left = 2*node ; right = 2*node + 1 ;
endTranche = PACK( node, end );
leftTranche = PACK( left << (elevation-1), right << (elevation-1) )
rightTranche = PACK( right << (elevation-1), node )
loopTranche = action ? leftTranche : rightTranche
tranche.push(endTranche, tmin)
tranche.push(loopTranche, tminAdvanced ) // subtree re-traversal with changed tmin
break ; // to next tranche
}
}
node <- postorder_next(node, elevation) // bit twiddling postorder
}
}
isect = csg.pop(); // winning intersect
https://bitbucket.org/simoncblyth/opticks/src/tip/optixrap/cu/csg_intersect_boolean.h
Opticks CSG Primitives : Closed Solids, Consistent Normals
Closed Solid as: implementation requires otherside intersect, Rigidly attached normals
| Type code |
Python name |
C++ nnode sub-struct |
|---|
| CSG_BOX3,CSG_BOX |
box3,box |
nbox |
| CSG_SPHERE,CSG_ZSPHERE |
sphere,zsphere |
nsphere,nzsphere |
| CSG_CYLINDER,CSG_DISC |
cylinder,disc |
ncylinder,ndisc |
| CSG_CONE |
cone |
ncone |
| CSG_CONVEXPOLYHEDRON |
convexpolyhedron |
nconvexpolyhedron |
| CSG_TRAPEZOID,CSG_SEGMENT |
trapezoid,segment |
nconvexpolyhedron |
- zsphere, cone, cylinder, disc : truncated shapes closed by endcaps <-- NOT OPTIONAL
- disc : avoids endcap degeneracy with very thin cylinders
- convexpolyhedron : defined by a set of planes, used for trapezoid and segment
- segment : prism shape used for deltaphi intersection
- !complemented (inside<->outside) solids handled by
special casing classification (cannot miss otherside).
Non-primitives, high level CSG definition avoids loadsa code
- ellipsoid : non-uniform scaling of sphere, polycone : union of cylinders and cones
- inner-radii : via subtraction, deltaphi-segment : via intersect with segment
Opticks CSG Primitives On Parade (GPU raytrace)

Three on right (Trapezoid, Segment, Icosahedron) all represented by planes with nconvexpolyhedron
Opticks CSG Serialized into OpticksCSG format (numpy buffers, json)
// tboolean-parade
from opticks.ana.base import opticks_main
from opticks.analytic.csg import CSG
args = opticks_main(csgpath="$TMP/$FUNCNAME")
container = CSG("box", param=[0,0,0,1200], boundary=args.container, poly="MC", nx="20" )
a = CSG("sphere", param=[0,0,0,100])
b = CSG("zsphere", param=[0,0,0,100], param1=[-50,60,0,0])
c = CSG("box3",param=[100,50,70,0])
d = CSG("box",param=[0,0,10,50])
e = CSG("cylinder",param=[0,0,0,100], param1=[-100,100,0,0])
f = CSG("disc",param=[0,0,0,100], param1=[-1,1,0,0])
g = CSG("cone", param=[100,-100,50,100])
h = CSG.MakeTrapezoid(z=100, x1=80, y1=100, x2=100, y2=80)
i = CSG.MakeSegment(phi0=0,phi1=45,sz=100,sr=100)
j = CSG.MakeIcosahedron(scale=100.)
prims = [a,b,c,d,e,f,g,h,i,j]
... // setting translations
CSG.Serialize([container] + prims, args.csgpath ) <-- write trees to file
- imported into C++ nnode tree by NCSG
Opticks CSG Primitives : What is included
OptiX/CUDA functions providing:
- axis aligned bounding box (AABB)
- intersect ray position (parametric t), surface normal
C++/nnode sub-struct methods
- signed distance function (SDF)
- parametric surface generation
4x4 Transforms on any node (translation/rotation/scaling)
Intersect inverse-transformed ray with un-transformed primitive
- parametric-t same in both frames
- inverse transform transposed brings normal back to world frame
Supporting non-uniform scaling requires rayDir not be be normalized (or assumed to be normalized) by primitives.
Dayabay ESR reflector : Deep CSG tree : disc with 9 holes

Subtraction of thin CSG_CYLINDER -> speckle in the hole
CSG_DISC implemented to handle disc like cylinders : intersects at middle (z1+z2)/2 and offsets, avoids issue


Coincident Faces are Primary Cause of Issues : Fake Intersects
Coincidences common (alignment too tempting?). To fix:
- A-B : grow correct dimension of subtracted shape
- A+B : grow smaller interface shape into bigger, making join
- case-by-case fixes straightforward, not so easy to automate
- WIP: automated coincidence finder/fixer

Signed Distance Functions (SDF) for Primitives and Composites
SDFs are composable using R-functions, eg min and max
- SDF(Union(A,B)) ~ min(SDF(A),SDB(B))
- SDF(Intersection(A,B)) ~ max(SDF(A),SDF(B))
- SDF(Difference(A,B)) ~ max(SDF(A),-SDF(B))
- SDF(!A) ~ -SDF(A)
Recursively applicable to CSG trees
-> analytic representation of arbitrary solid
SDFs enable geometry querying/debugging:
- classification of point wrt solid
- select surface points from primitives
- obtain bounding box from surface points
- polygonization by isosurface extraction
- fast OpenGL rasterized visualization
Rvachev-functions (R-functions) : sign uniquely determined by signs of arguments -> parallel CSG operations
Translated Solid Debugging : Using py/bash/c++ Code Generation
NScanTest : Find Problem Solids by SDF Scanning
Count SDF zero crossings along scanlines (expect even)
- odd crossings -> coincidence false zeros
~5/249 odd solids : not yet handled by auto-uncoincidence
GScene::compareMeshes : Bounding Box comparisons
G4Poly(via G4DAE) vs Opticks parsurf (parametric surface)
- 25/249 solids with max bbox dimension discrepancy > 1mm
- causes of ~20 not explained by coincidence, presume:
- G4Poly bugs(*) : some clear missing cylinders from unions
- parsurf bbox imprecision (very different size sub-objects)
NEXT STEP: direct intersect comparison between Opticks/G4 CSG implementations for definitive answers
(*) could also be G4DAE export of G4Poly
Full Analytic GDML Geometry Translation Workflow
General CSG ray tracing on GPU allows operation from GDML files
gdml2gltf.py (opticks.analytic.sc)
- wraps GDML in python
- translates G4 solids into OpticksCSG
- collects structure into glTF scene tree
- scene tree refers to OpticksCSG solids as extras
- writes OpticksCSG for each solid together with glTF to file
NScene
- loads glTF structure into nd scene tree
NCSG
- loads OpticksCSG into nnode trees for each solid
GScene/OScene
- converts into OptiX GPU buffers
glTF : (GL Transmission Format) "JPEG of 3D" : efficient transmission and loading of 3D scenes and models,
https://www.khronos.org/gltf
Opticks Analytic Daya Bay Near Site, GPU Raytrace Screenshots
GPU Raytrace on following pages are for Daya Near Site Geometry, auto translated from GDML
- Looks similar to raytraces shown previously, BUT: there is a huge difference
- No triangles -> No approximation -> Fully Analytic
- Intersects should match Geant4 (if not its a bug to fix)
- Opticks CSG code runs for every pixel, picking the intersects
- significantly slower that the triangulated approach (GPUs love triangles)
- very new, no optimization yet
- speckle effect is caused by coincident surfaces
General Translation Machinery
- straightforward to apply to JUNO GDML
- however : expect every new geometry will yield new issues
- lots of geometry debugging tools ready to be used
Scene Debugging : NSceneLoadTest
- classify child volume surface points against parent volume SDF (or v.v),
look for impingments/coincidences
Opticks Analytic Daya Bay Near Site, GPU Raytrace (3)
Opticks Analytic Daya Bay Near Site, GPU Raytrace (1)
Opticks Analytic Daya Bay Near Site, GPU Raytrace (0)
Opticks Analytic Daya Bay Near Site, GPU Raytrace (2)
July 2017 Summary

Opticks enables Geant4 based simulations to benefit from optical photon simulation
taking effectively zero time and zero CPU memory,
due to massive parallelism made accessible by NVIDIA OptiX.
GDML detector geometry is auto translated into a GPU optimized analytic form,
fully equivalent to the source geometry.
- The more photons the bigger the overall speedup (99% -> 100x)
- Drastic speedup -> better detector understanding -> greater precision
- Large PMT based neutrino experiments, such as JUNO, can benefit the most
https://bitbucket.org/simoncblyth/opticks
Context Pages
- Optical Photon Simulation Problem
- Ray Traced Image Synthesis ≈ Optical Photon Simulation
- Open Source Opticks
- YouTube Video
For more on Opticks see
https://bitbucket.org/simoncblyth/opticks
[1] LLR Workshop, https://simoncblyth.bitbucket.io/env/presentation/opticks_gpu_optical_photon_simulation_nov2016_llr.html
Summary from LLR Workshop (Nov 2016)
Opticks enables Geant4 based simulations to benefit from optical photon simulation
taking effectively zero time and zero CPU memory,
thanks to massive parallelism made accessible by NVIDIA OptiX.
- The more photons the bigger the overall speedup (99% -> 100x)
- Drastic speedup -> better detector understanding -> greater precision
- Large PMT based neutrino experiments, such as JUNO, can benefit the most
https://bitbucket.org/simoncblyth/opticks
JPMT Before Contact 2
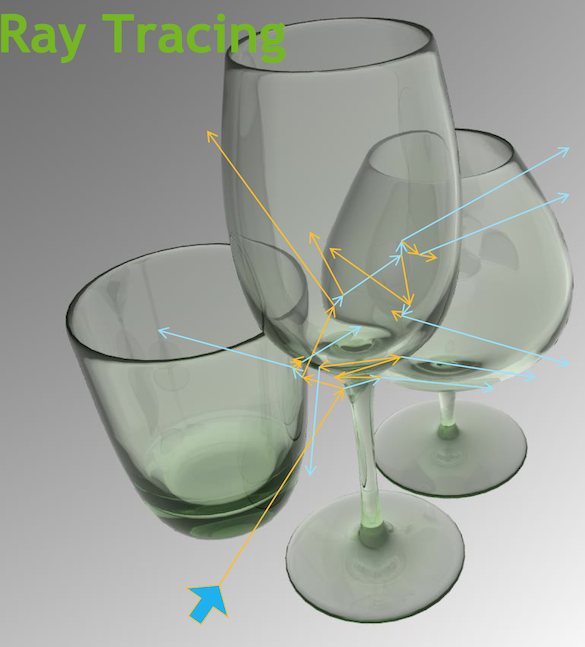
Ray Traced Image Synthesis ≈ Optical Photon Simulation
- Geometry, light sources, optical physics ->
- pixel values at image plane
- photon parameters at detectors (eg PMTs)
- Ray tracing has many applications :
- advertising, design, entertainment, games,...
- BUT : most ray tracers just render images
- NVIDIA OptiX had foresight to be less specific:
- general geometry intersection API
- OptiX is to ray tracing what OpenGL is to rasterization
- rasterization
- project 3D primitives onto 2D image plane, combine fragments into pixel values
- ray tracing
- cast rays thru image pixels into scene, recursively reflect/refract with
geometry intersected, combine returns into pixel values
OpticksDocs
Debugging Coincident Subtractions
Switching subtraction into union with complemented -> can see whats subtracted.

Slides Booted to Backup
- Various Polygonization Approaches
Various Polygonization Approaches
Several Integrations of Open Source Polygonizations
- Marching Cubes
- fill bbox with cubes, generate triangles for cubes with sign changes,
fixed resolution (miss features or too many tris)
- Dual Contouring
- multiresolution using octree (slow, finnicky)
- Implicit Mesher
- finds and follows surface, fast, fixed resolution, (needs help in finding)
My own attempt (WIP)
- Hybrid Mesher
- combining SDF classification with parametric generation, (complicated mesh joining)