Outline

- Introduction
- JUNO Optical Photon Simulation Problem...
- NVIDIA Marbles at Night : RTX Demo ; NVIDIA Ampere : 2nd Generation RTX
- GPU Ray Tracing APIs Converging
- RTX Execution Pipeline : Common to DirectX RT, VulkanRT, NVIDIA OptiX
- Spatial Index Acceleration Structure
- Two-Level Hierarchy : Instance transforms (TLAS) over Geometry (BLAS)
- Opticks : Structural Geometry
- Geant4 + Opticks Hybrid Workflow
- NPY Serialization : Fundamental to Opticks Geometry Model ; NumPy Example
- Translation 1st Step : Geant4 -> Opticks/GGeo : 1->1 conversions
- Translation 2nd Step : Opticks/GGeo Instancing : "Factorized" Geometry
- Ray Intersection with Transformed Object -> Geometry Instancing
- OpenGL Mesh Instancing ; OptiX Ray Traced Instancing
- Opticks Solids : CSG, Constructive Solid Geometry
- G4VSolid -> CUDA Intersect Functions for ~10 Primitives
- G4Boolean -> CUDA/OptiX Intersection Program Implementing CSG
- (CSG details relegated to "Extras")
- Opticks Material/Surface Properties : Boundary Texture
- Opticks vs Geant4 : Extrapolated G4 times compared to Opticks with RTX ON/OFF
- Overview + Links
Outline Extras
- Opticks Solids : CSG, Constructive Solid Geometry
- Constructive Solid Geometry (CSG) : Shapes defined "by construction"
- CSG : Which primitive intersect to pick ?
- CSG Complete Binary Tree Serialization -> simplifies GPU side
- Evaluative CSG intersection Pseudocode : recursion emulated
- CSG Deep Tree : JUNO "fastener"
- CSG Deep Tree : height 11 before balancing, too deep for GPU raytrace
- CSG Deep Tree : Positivize tree using De Morgans laws
- CSG Deep Tree : height 4 after balancing, OK for GPU raytrace
- CSG Examples
- Torus : much more difficult/expensive than other primitives
- Torus : different artifacts as change implementation/params/viewpoint
GPU Ray Tracing (RT) APIs Converging
Driver Updates : Independant of Application
- new GPU support
- performance improvements
Three Similar Interfaces over same RTX tech:
NVIDIA OptiX (Linux, Windows) [2009]
- CUDA header only access to Driver functionality
Vulkan RT (Linux, Windows) [final spec 2020]
- cross-vendor cross-platform RT
Microsoft DXR : DirectX 12 Ray Tracing (Windows) [2018]
- enhancing visual quality of realtime games
Metal Ray Tracing API (macOS) [introduced 2020[1]]
- Very different Integrated GPU : Apple Silicon M1 GPU
- BUT: similar API
[1] https://developer.apple.com/videos/play/wwdc2020/10012/
RTX Execution Pipeline : Common to DirectX RT, Vulkan NV RT, OptiX
Acceleration Structure (AS) traversal is central to pipeline performance
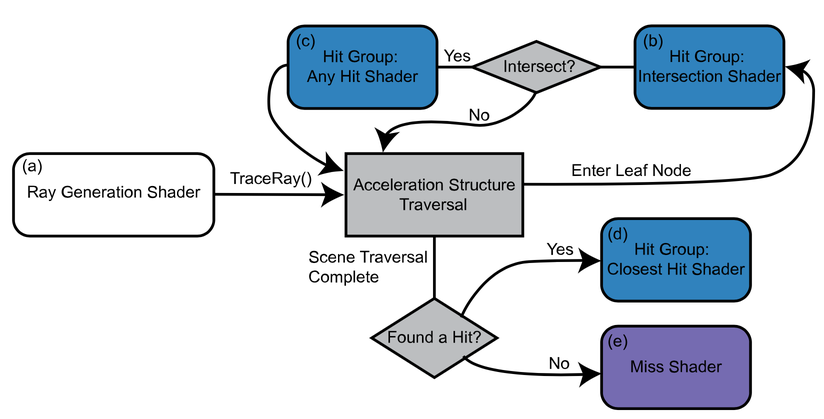
"The RTX Shader Binding Table (SBT) Three Ways", Will Usher
RG : Ray Generation
IS : Intersect
CH : Closest Hit
AH : Any Hit
MS : Miss
GPU Opticks
- RG
- CerenkovScintillation"bounce" loop
- IS
- primitives, CSG
- CH
- IS->RG
Two-Level Hierarchy : Instance transforms (TLAS) over Geometry (BLAS)
OptiX supports multiple instance levels : IAS->IAS->GAS BUT: Simple two-level is faster : works in hardware RT Cores
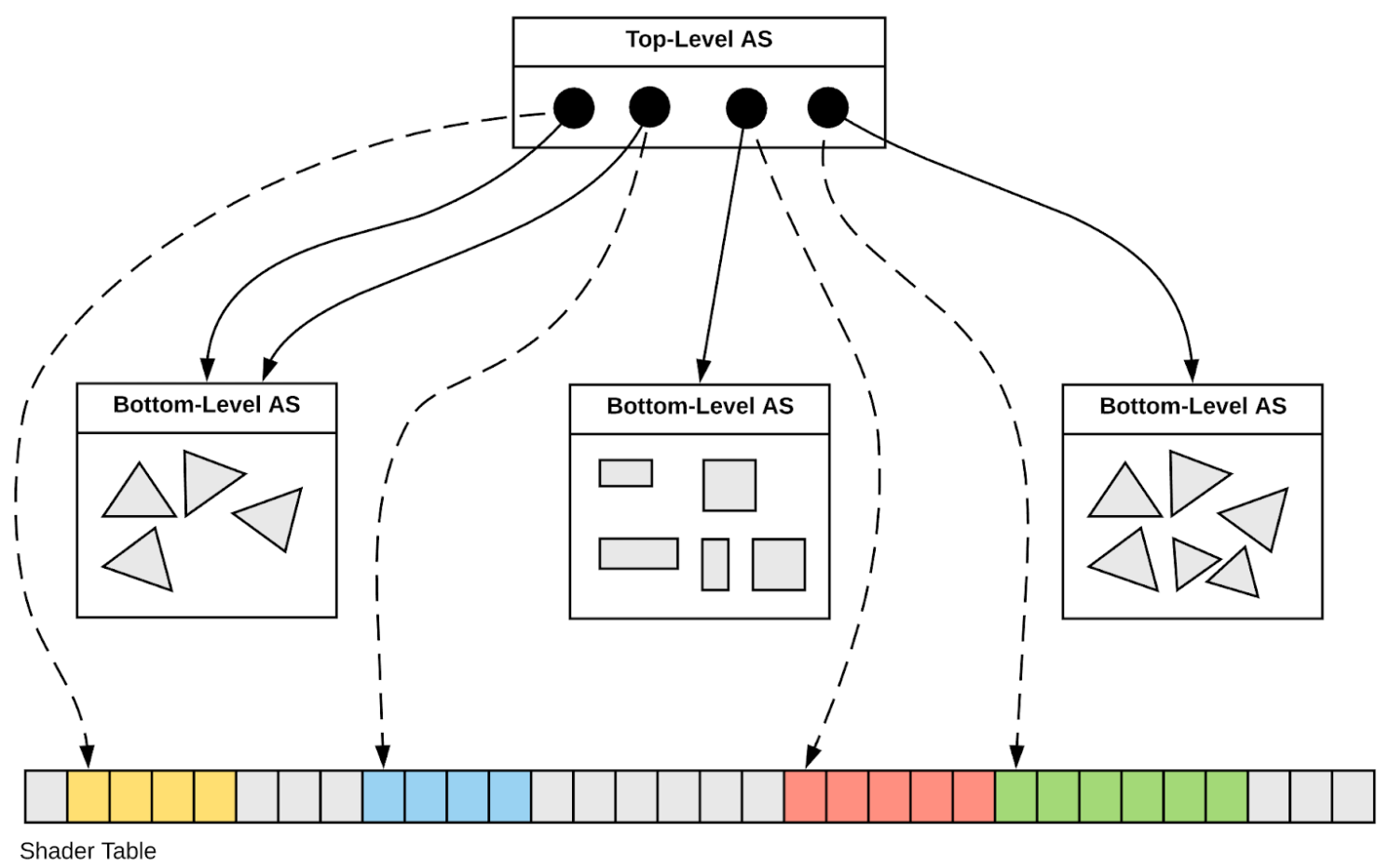
- AS
- Acceleration Structure
- TLAS (IAS)
- 4x4 transforms, refs to BLAS
- BLAS (GAS)
- triangles : vertices, indicescustom primitives : AABB
- AABB
- axis-aligned bounding box
SBT : Shader Binding Table
Flexibly binds together:
- geometry objects
- shader programs
- data for shader programs
Hidden in OptiX 1-6 APIs
Optimizing Geometry : Split BLAS to avoid overlapping bbox
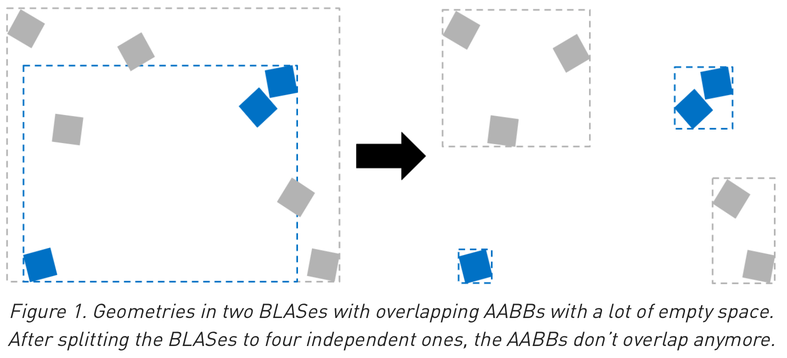
Optimization : deciding where to draw lines between:
- structure and solid (IAS and GAS)
- solids within GAS (bbox choice to minimize traversal intersection tests)
Where those lines are drawn defines the AS
https://developer.nvidia.com/blog/best-practices-using-nvidia-rtx-ray-tracing/
Optimizing Geometry : Merge BLAS when lots of overlaps
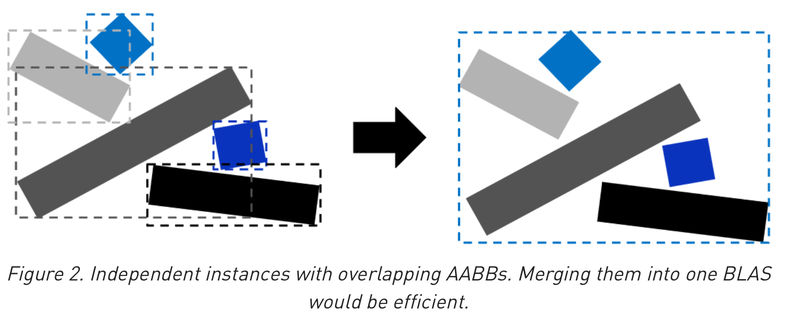
- lots of overlapping forces lots of intersections to find closest
- but too few bbox means the AS cannot help to avoid intersect tests
- balance required : needs experimentation and measurement to optimize
https://developer.nvidia.com/blog/best-practices-using-nvidia-rtx-ray-tracing/
Ray Intersection with Transformed Object -> Geometry Instancing
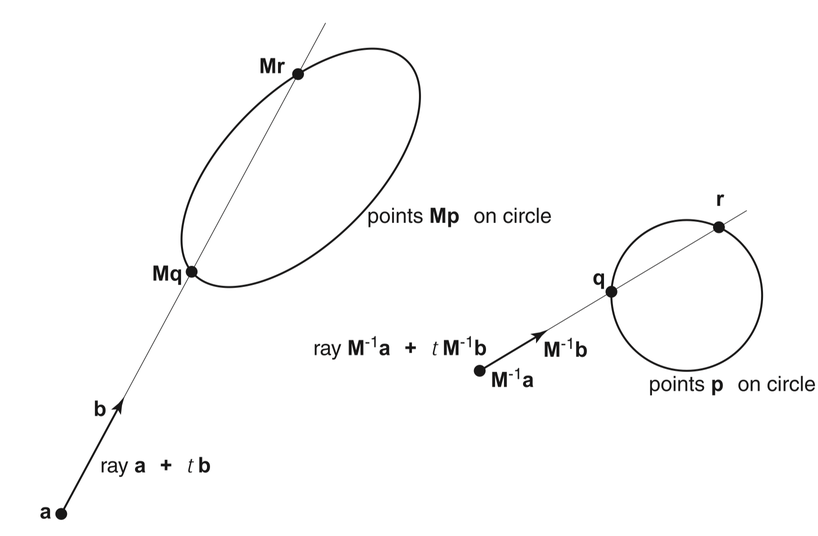
Fig 13.5 "Realistic Ray Tracing", Peter Shirley
Advantages apply equally to acceleration structures
Equivalent Intersects -> same t
- ray with ellipsoid : M*p
- M-1 ray with sphere : p
Local Frame Advantages
- simpler intersect (sphere vs ellipsoid)
- closer to origin -> better precision
Geometry Instancing Advantages
- many objects share local geometry
- orient+position with 4x4 M
- huge VRAM saving, less to copy
Requirements
- must not normalize ray direction
- normals transform differently
- N' = N * M-1T
- (due to non-uniform scaling)
G4VSolid -> CUDA Intersect Functions for ~10 Primitives
- 3D parametric ray : ray(x,y,z;t) = rayOrigin + t * rayDirection
- implicit equation of primitive : f(x,y,z) = 0
- -> polynomial in t , roots: t > t_min -> intersection positions + surface normals

Sphere, Cylinder, Disc, Cone, Convex Polyhedron, Hyperboloid, Torus, ...
G4Boolean -> CUDA/OptiX Intersection Program Implementing CSG
dot(normal,rayDir) -> Enter/Exit
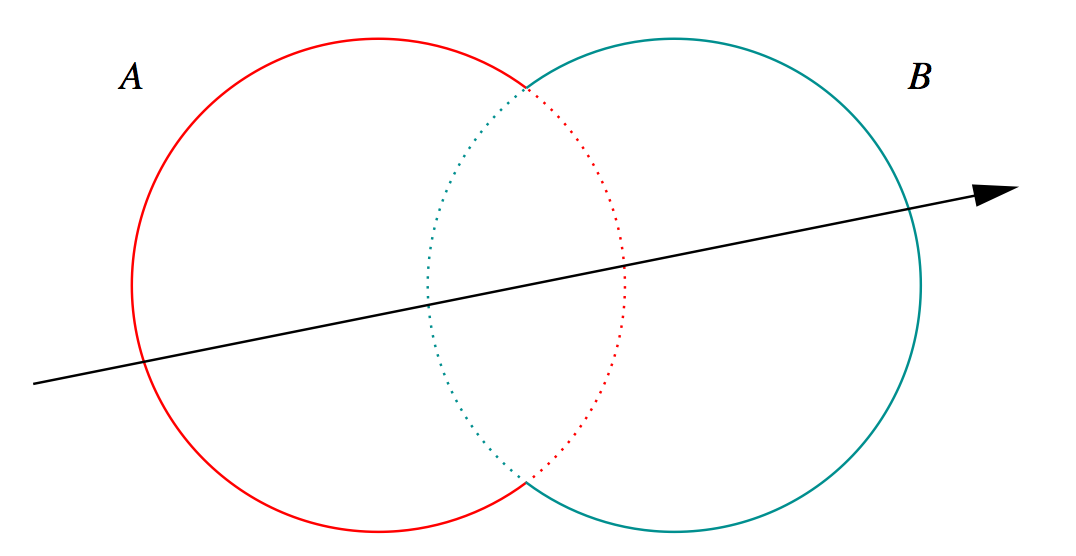
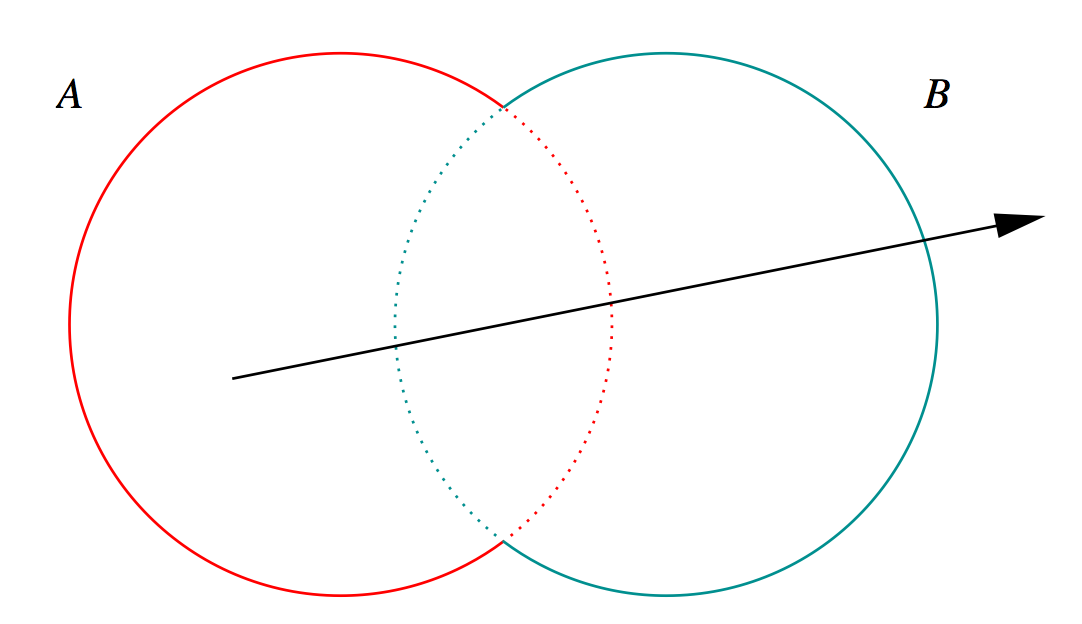
- A + B boundary not inside other
- A * B boundary inside other
Complete Binary Tree, pick between pairs of nearest intersects:
| UNION tA < tB | Enter B | Exit B | Miss B |
|---|---|---|---|
| Enter A | ReturnA | LoopA | ReturnA |
| Exit A | ReturnA | ReturnB | ReturnA |
| Miss A | ReturnB | ReturnB | ReturnMiss |
- Nearest hit intersect algorithm [1] avoids state
- sometimes Loop : advance t_min , re-intersect both
- classification shows if inside/outside
- Evaluative [2] implementation emulates recursion:
- recursion not allowed in OptiX intersect programs
- bit twiddle traversal of complete binary tree
- stacks of postorder slices and intersects
- Identical geometry to Geant4
- solving the same polynomials
- near perfect intersection match
- [1] Ray Tracing CSG Objects Using Single Hit Intersections, Andrew Kensler (2006)
- with corrections by author of XRT Raytracer http://xrt.wikidot.com/doc:csg
- [2] https://bitbucket.org/simoncblyth/opticks/src/tip/optixrap/cu/csg_intersect_boolean.h
- Similar to binary expression tree evaluation using postorder traverse.
Summary : Opticks Detector Geometry

Opticks : state-of-the-art GPU ray tracing applied to optical photon simulation and integrated with Geant4, giving a leap in performance that eliminates memory and time bottlenecks.
- Drastic speedup -> better detector understanding -> greater precision
- any simulation limited by optical photons can benefit
- more photon limited -> more overall speedup (99% -> 100x)
| https://bitbucket.org/simoncblyth/opticks | code repository |
| https://simoncblyth.bitbucket.io | presentations and videos |
| https://groups.io/g/opticks | forum/mailing list archive |
| email:opticks+subscribe@groups.io | subscribe to mailing list |
Constructive Solid Geometry (CSG) : Shapes defined "by construction"
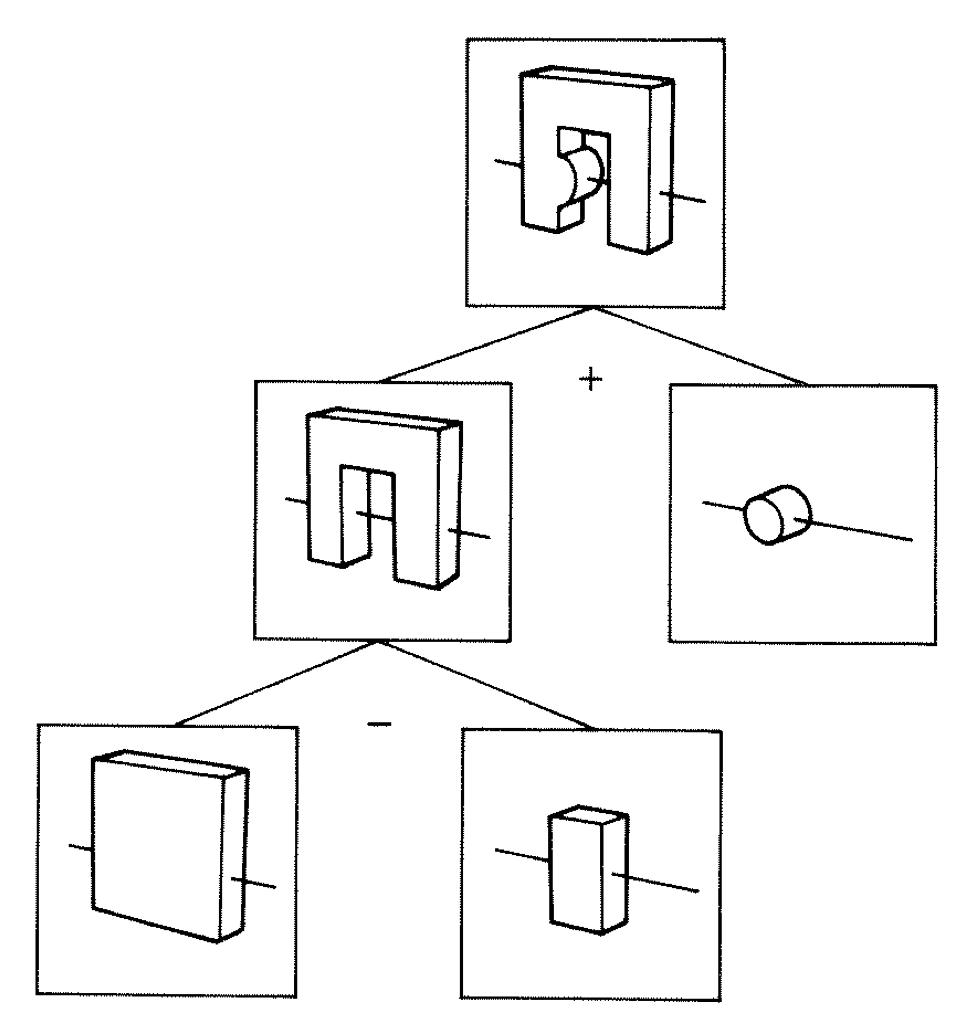
Primitives combined via binary operators
Simple by construction definition, implicit geometry.
- A, B implicit primitive solids
- A + B : union (OR)
- A * B : intersection (AND)
- A - B : difference (AND NOT)
- !B : complement (NOT) (inside <-> outside)
CSG expressions
- non-unique: A - B == A * !B
- represented by binary tree, primitives at leaves
3D Parametric Ray : ray(t) = r0 + t rDir
Ray Geometry Intersection
- primitive : find t roots of implicit eqn
- composite : pick primitive intersect, depending on CSG tree
How to pick exactly ?
CSG : Which primitive intersect to pick ?
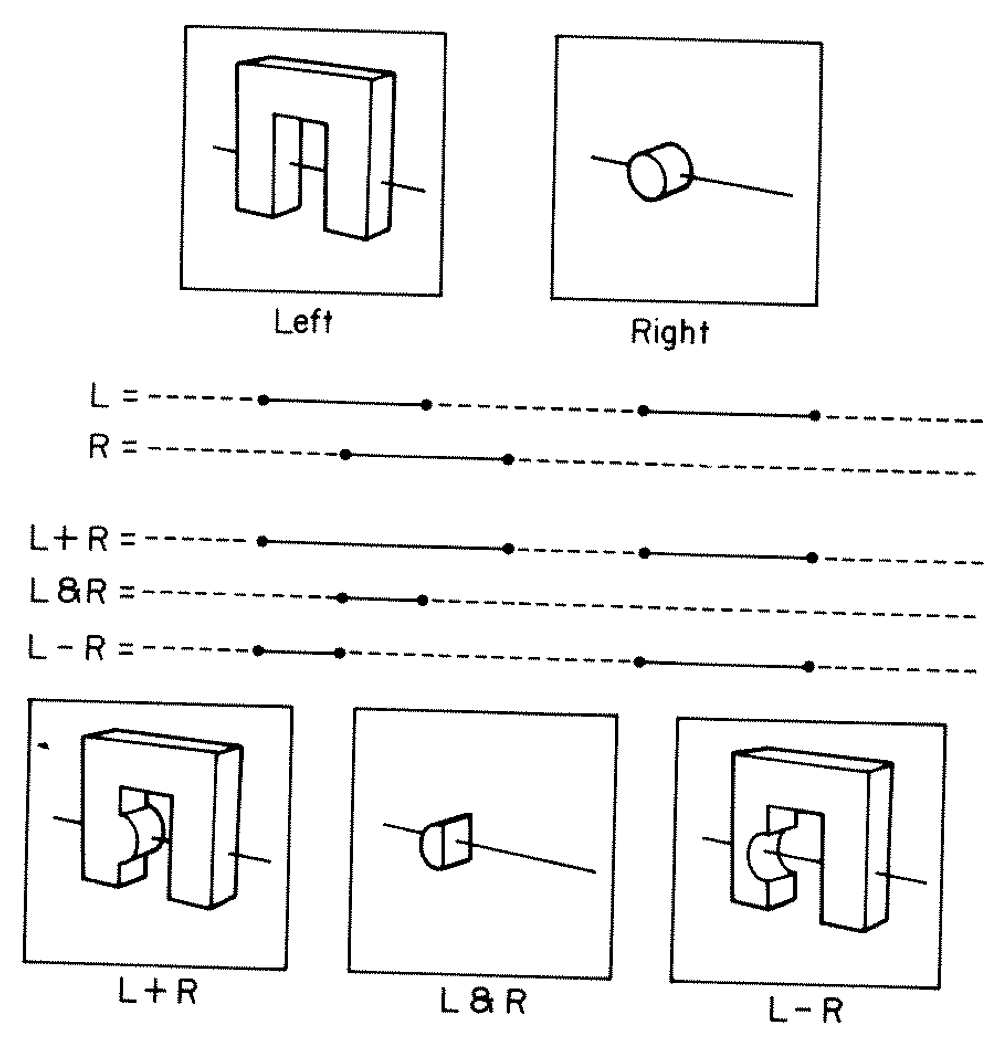
Classical Roth diagram approach
- find all ray/primitive intersects
- recursively combine inside intervals using CSG operator
- works from leaves upwards
Computational requirements:
- find all intersects, store them, order them
- recursive traverse
BUT : High performance on GPU requires:
- massive parallelism -> more the merrier
- low register usage -> keep it simple
- small stack size -> avoid recursion
Classical approach not appropriate on GPU
CSG Deep Tree : JUNO "fastener"

Torus : much more difficult/expensive than other primitives

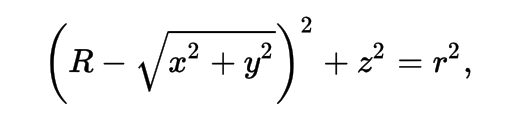
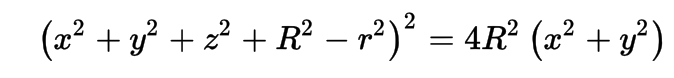
3D parametric ray : ray(x,y,z;t) = rayOrigin + t * rayDirection
- ray-torus intersection -> solve quartic polynomial in t
- A t^4 + B t^3 + C t^2 + D t + E = 0
High order equation
- very large difference between coefficients
- varying ray -> wide range of very coefficients
- numerically problematic, requires double precision
- several mathematical approaches used, work in progress
Best Solution : replace torus
- eg model PMT neck with hyperboloid, not cylinder-torus
Torus : different artifacts as change implementation/params/viewpoint
- Only use Torus when there is no alternative
- especially avoid CSG combinations with Torus


