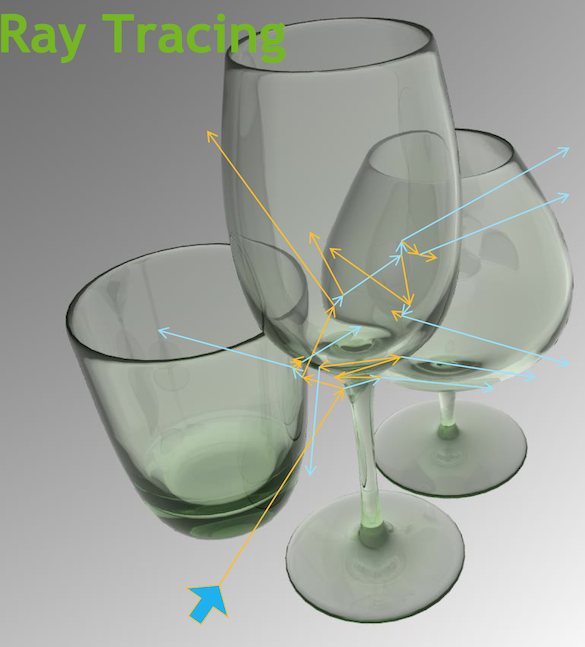
Opticks : GPU Accelerated Optical Photon Simulation for JUNO and Other Experiments
Opticks: GPU Accelerated Optical Photon Simulation for JUNO and Other Experiments
Open source, https://github.com/simoncblyth/opticks

On behalf of the JUNO Collaboration
Simon C Blyth, IHEP, CAS — 28th CHEP Conf, Chulalongkorn Univ, Bangkok, Thailand — (27 May 2026)
Outline

- Optical Photon Simulation Context
- (JUNO) Optical Photon Simulation Problem...
- Optical Photon Simulation ≈ Ray Traced Image Rendering
- NVIDIA RTX PRO 6000 Blackwell
- Four NVIDIA RTX Gen : Ray Tracing : ~2x every ~2 yrs
- Opticks Optical simulation directly scales with ray tracing speed
- NVIDIA OptiX : Ray Tracing Engine -- Accessible GPU Ray Tracing
- Geant4 + Opticks + NVIDIA OptiX : Hybrid Workflow
- Amdahl 'Law' : Overall Speedup S(p,n) for Parallel Fraction p and Parallized Speedup n
- Simulation of High Energy Events, eg: Multi-Muon
- Photons from muon crossing JUNO Scintillator
- Recent Opticks Enhancements : directed by Muon Production Experience
- GPU Hit Merging : High Level Parallelization with CUDA Thrust
- GPU Hit Merging : Avoids hiding Opticks performance
- Opticks + JUNOSW : Testing as Geometry and Models continue to Evolve
- EMF Compensation Coils, Water Distributor, "Simtrace"
- Geant4 + Opticks + NVIDIA OptiX : Production Scaling ?
- Geant4 + Opticks + NVIDIA OptiX : Monolith x4, x16
- OpticksClients + OpticksService : Share GPUs
- Opticks "Optical Core" => Server, "Periphery" => Client
- NP_CURL.h : Array transport via HTTP POST
- Opticks Server Prototype : python + FastAPI + nanobind + CSGOptiX
- NVIDIA Triton Inference Server (aka Dynamo-Triton)
- Summary + Links
(JUNO) Optical Photon Simulation Problem...
Opticks solves this using GPU ray tracing via NVIDIA OptiX
Optical Photon Simulation ≈ Ray Traced Image Rendering
- simulation
- photon parameters at sensors (PMTs)
- rendering
- pixel values at image plane
Much in common : geometry, light sources, optical physics
- both limited by ray geometry intersection, aka ray tracing
Many Applications of ray tracing :
- advertising, design, architecture, films, games,...
- -> huge efforts to improve hw+sw over 30 yrs
NVIDIA RTX PRO 6000 Blackwell
Blackwell(4th Gen RTX) vs Ada(3rd Gen RTX):
- fourth-gen RT Cores : ray tracing ~doubled
- 96GB GDDR7 : internal bandwidth ~doubled (1792 GB/s)
- PCIe 5.0 : external bandwidth ~doubled
- fifth-gen Tensor Cores : add FP4 (4-bit float), AI ~doubled
- add Multi-Instance GPU (MIG) support
- virtual "split" into four instances
- power doubled (600W)
Server Edition
Four NVIDIA RTX Gen : Ray Tracing : ~2x every ~2 yrs
| Gen |
Model |
Year |
VRAM |
CUDA
Cores |
RT (Ray tracing) |
|---|
| GB |
GB/s |
Cores |
TFLOPS |
Rise |
|---|
| Turing |
Quadro RTX 6000 |
2018 |
24 |
672 |
4,608 |
72 |
~34 |
[1] |
| Ampere |
RTX A6000 |
2020 |
48 |
768 |
10,752 |
84 |
~76 |
2.2x |
| Ada |
RTX 6000 Ada |
2023 |
48 |
960 |
18,176 |
142 |
~211 |
2.7x |
| Blackwell |
RTX PRO 6000 |
2025 |
96 |
1792 |
24,064 |
188 |
~380 |
1.8x |
- RT Cores: fixed-function ASICs dedicated to ray tracing : bbox intersection, ray-triangle intersection, BVH traversal, ...
NVIDIA RT TFLOPS: synthetic ray trace metric -- Turing -> Blackwell : 11x
(Equivalent FLOPs per Ray Intersection) x (Intersections per clock) x (Core Clock) x (Number of RT Cores)
[1] baseline : 2018 "World's First Ray-Tracing GPU -- 10 Gigarays/sec"
AB_Substamp_ALL_Etime_vs_Photon_rtx_gen1_gen3.png
Event Time(s) vs PH(M)
| PH(M) |
G1 |
G3 |
G1/G3 |
|---|
| 1 |
0.47 |
0.14 |
3.28 |
| 10 |
0.44 |
0.13 |
3.48 |
| 20 |
4.39 |
1.10 |
3.99 |
| 30 |
8.87 |
2.26 |
3.93 |
| 40 |
13.29 |
3.38 |
3.93 |
| 50 |
18.13 |
4.49 |
4.03 |
| 60 |
22.64 |
5.70 |
3.97 |
| 70 |
27.31 |
6.78 |
4.03 |
| 80 |
32.24 |
7.99 |
4.03 |
| 90 |
37.92 |
9.33 |
4.06 |
| 100 |
41.93 |
10.42 |
4.03 |
Optical simulation 4x faster 1st->3rd gen RTX
3rd gen Ada : 100M ph sim. in 10s [TMM PMT model, Custom CSG]
Opticks optical simulation speed directly scales with ray tracing speed.
TMM : Transfer-Matrix Method
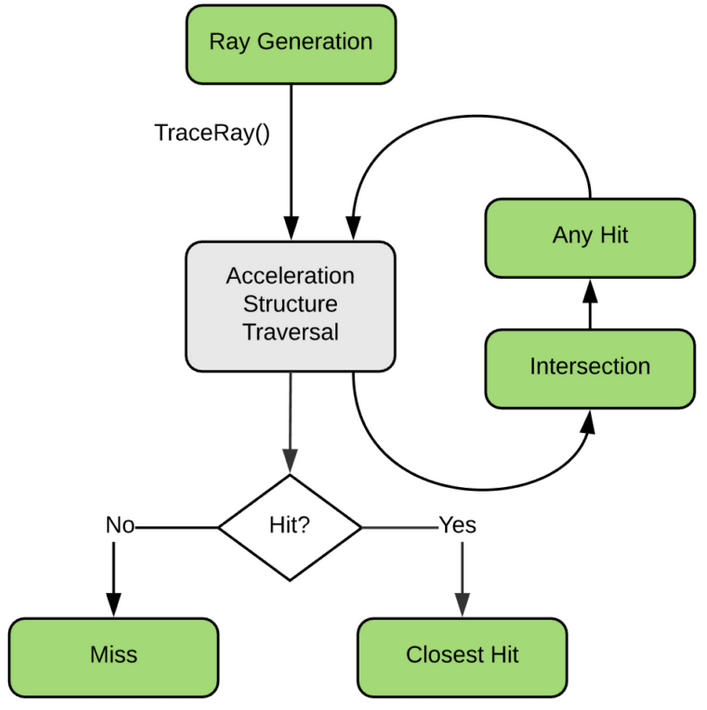
NVIDIA® OptiX™ Ray Tracing Engine -- Accessible GPU Ray Tracing
OptiX makes GPU ray tracing accessible
- Programmable GPU-accelerated Ray-Tracing Pipeline
- Single-ray shader programming model using CUDA
- ray tracing acceleration using RT Cores (RTX GPUs)
- "...free to use within any application..."
OptiX features
- stateless, multi-threaded and asynchronous
- built-in triangles, user-defined custom primitives
- acceleration structure creation + traversal (eg BVH)
- instanced geometry + acceleration structures
- compiler optimized for GPU ray tracing
User provides (Green):
- ray generation, geometry bounding boxes
- custom primitive intersect functions
- instance transforms
Latest Release : NVIDIA® OptiX™ 9.1.0 (Dec 2025)
- NVIDIA R590+ driver
- OptiX 6 support removed from drivers R590+
Geant4 + Opticks + NVIDIA OptiX : Hybrid Workflow
Opticks enables Geant4 based simulation to offload optical photon simulation to the GPU
NVIDIA GPU ray tracing of billions[1] of rays per second applied to optical simulation
[1] Actual performance depends on geometry and its modelling, JUNO optical simulation speedups > 1000x Geant4 have been measured
amdahl300
Simulation of High Energy Events, eg: Multi-Muon
Simulation of High Energy Events, eg: Multi-Muon
GEOM_J25_4_0_opticks_Debug_cxr_min_muon_cxs_20250707_112242.png
EVT=muon_cxs cxr_min.sh #12 : photons from muon crossing JUNO Scintillator
GEOM_J25_4_0_opticks_Debug_cxr_min_muon_cxs_20250707_112243.png
EVT=muon_cxs cxr_min.sh #13
GEOM_J25_4_0_opticks_Debug_cxr_min_muon_cxs_20250707_112244.png
EVT=muon_cxs cxr_min.sh #14
Large counts motivate merging of hits with same (pmtid,timebucket) : adding counts and keeping earliest time
Recent Opticks Enhancements : directed by Muon Production Experience
Add Opticks "lite" photons : used with JUNOSW "Muon" hits (--pmt-hit-type 2)
- Opticks sphotonlite (16 bytes), 4x smaller than sphoton (64 bytes)
- reduce overheads for big events, photons per launch ~250M -> ~500M [32 GB VRAM]
Removed 32-bit max photon limits -> simulation of giga optical photon events
- handles monster double+ muon events, tested with > 8 billion photon events
- events with more photons than fit in VRAM => multiple launches
Add CUDA implementation of hit merging (thrust::sort_by_key,reduce_by_key)
- merge hits onto same PMT within time buckets (eg: 1 ns)
- hits selected + merged on GPU
- async CUDA impl : cudaStream_t cudaEvent_t with future object pattern
- benefit twice : reduce download time (as merged) + avoid slow CPU merge
- multi-launch events : concatenate merged hits, then QEvt::FinalMerge_async
GPU Hit Merging : High Level Parallelization with CUDA Thrust
struct key_functor { // Bitwise-OR (pmtid,timebucket)
float timewindow;
uint64_t operator()(const sphotonlite& p) const // 16+48 = 64
{
return (uint64_t(p.identity()) << 48) | uint64_t(p.time/timewindow);
}
};
Opticks/sysrap SPM::merge_partial_select using CUDA Thrust (higher level C++ way to use CUDA)
| Thrust method |
Action |
Note |
|---|
| copy_if |
photon -> hit |
using flagmask |
| transform |
hit -> key |
bitwise-OR (pmtid, timebucket) |
| sort_by_key |
hit, key -> hit |
hit ordered with same (pmtid,timebucket) contiguous |
| reduce_by_key |
hit, key -> hitmerged |
merge two hit : earlier time, sum hitcount |
https://github.com/simoncblyth/opticks/blob/master/sysrap/SPM.cu
https://github.com/simoncblyth/opticks/blob/master/sysrap/sphotonlite.h
Opticks + JUNOSW : Testing as Geometry and Models continue to Evolve
Recent JUNO Simulation Geometry Additions:
- Water Distributor System
- EM Field (EMF) compensation coils
- Extra Water Pool 8-inch PMTs
- ...
Opticks Unit tests : class/struct level "opticks-t"
~221 ctest taking ~90s (geom from latest Opticks+JUNOSW release)
Integration Tests : JUNOSW vs Opticks+JUNOSW
- A: Opticks + JUNOSW : write Opticks SEvt NumPy files
- B: U4Recorder + JUNOSW : write Opticks SEvt from Geant4
- A-vs-B photon history chi-squared
- deviations reveal issues (typically geometry problems)
- GPU workstation configured as gitlab CI runner [NEW]
- Dedicated "OJ" repo for integration test scripts
AIM: automated scheduled validation
- cast results as junit report (available in gitlab CI free-tier)
- automated problem finding ✔, automated fix ✘
- fix judgement : change source OR generalize translation
EMF2 3
EMF2 3 EMF Compensation Coils : View from bottom of pool (v. large vol. excluded)
WDP 4
WDP 4 : Water Distributor at top of CD
WDP 6
WDP 6 : Water Distributor at bottom of CD
LWDS : Simtrace Split Snake
Precise "Simtrace" 2D sliced view - Water Distributor and pipes at bottom of JUNO CD
Scaling Opticks
Geant4 + Opticks + NVIDIA OptiX : Production Scaling ?
- hard to make good use of GPU resources, gets harder with each generation
- monolithic scaling Opticks ?
- GPU idle while : Geant4 init + non-optical simulation : wasteful of GPU resources
=> Client-Server architecture
- separate GPU optical simulation into OpticksServer
- share server between CPU nodes
Geant4 + Opticks + NVIDIA OptiX : Hybrid Workflow 2x2 ?
Geant4 + Opticks + NVIDIA OptiX : Monolith x4 ?
Geant4 + Opticks + NVIDIA OptiX : Hybrid Workflow 4x4 ?
Geant4 + Opticks + NVIDIA OptiX : Monolith x16 ?
"Monolithic" scaling : very inefficient use of scarce GPU resources
OpticksClients + OpticksService : Share GPUs
Client.png
Opticks "Optical Core" => Server, "Periphery" => Client
| Package |
Role |
Client |
Server |
|---|
| SysRap |
Geometry and event types, array NP.hh |
✔ |
✔ |
| CSG |
CPU/GPU geometry model |
✔ |
✔ |
| QUDARap |
CUDA optical simulation |
✘ |
✔ |
| CSGOptiX |
OptiX 7+ geometry, GPU ray trace |
✘ |
✔ |
| U4 |
Geometry convert, collect gensteps, return hits |
✔ |
✘ |
| G4CX |
Top level interface, acts via SSimulator |
✔ |
✘ |
| |
Client |
Server |
|---|
| depends: |
NVIDIA GPU + CUDA + OptiX |
Geant4, U4, G4CX |
| depends: |
libcurl 7.76.1+, NP_CURL.h |
python, FastAPI, nanobind |
| SSimulator: |
SOpticksClientSimulator |
CSGOptiX |
Client build from common Opticks codebase with OPTICKS_CONFIG=Client
- OpticksClient use just like OpticksFull(monolithic) - simulate via network to GPU node
NP_CURL.h : Array transport via HTTP POST
Basis for Opticks Client - using libcurl 7.76.1+ (2021) - default in many Linux distro
- NP* NP_CURL::transformRemote( NP* a, size_t index, size_t count )
- HTTP POST array to endpoint, receive array in response, metadata in headers
NP.hh : C++ array with NumPy serialization (Opticks numerical base), NP_CURL.h headers:
| HTTP metadata headers |
Note |
|---|
| x-opticks-shape |
array shape eg "(10,6,4)" for 10 gensteps |
| x-opticks-dtype |
eg "float32" |
| x-opticks-index |
eg eventID controlling random number stream offsets |
| x-opticks-count |
eg: number of photons in genstep, cost of request |
| x-opticks-meta |
general eg geometry root node digest - assert same geometry |
HTTP 429, 503 : Too Many Requests, Service Unavailable (temporary downtime)
- follows Retry-After: <seconds> header suggestion
https://github.com/simoncblyth/np/blob/master/NP_CURL.h -- https://github.com/simoncblyth/np/blob/master/NP.hh
Opticks Server Prototype : python + FastAPI + nanobind + CSGOptiX
CSGOptiX/tests/CSGOptiXService_FastAPI_test/CSGOptiXService_FastAPI_test.sh
- FastAPI : ASGI python web framework
- nanobind : python <=> C++ (Using uv, pip)
- opticks/CSG : load persisted geometry
- opticks/CSGOptiX : simulate
Prototype client + service operational
- load testing with k6 https://k6.io
- started adding concurrent CUDA support to Opticks
- WIP: extend async CUDA to all Opticks GPU usage
"Roll your own" Prototype Server : Educational, BUT:
- difficult to robustly serve many clients
- => unsuitable for MC production campaign (?)
- PLAN : compare with widely used open source server : NVIDIA Triton Inference Server
NVIDIA Triton Inference Server (aka Dynamo-Triton)
Triton[1] : open-source, designed to accelerate AI deployment at scale
- despite "Inference", "AI" : is flexible async tensor server
- NVIDIA maintained open source server software
- dynamic batching : requests queued and combined in batch
- multi-GPU support, concurrency
- widely used : tech, financial, manufacturing companies
Wrap Opticks as Custom C++ Triton Backend "model(s)" ?
Make request load like inference : smaller, more uniform
- Make requests during genstep collection :
- => tunable max_slots
- decouple compute from physics
- High GPU utilization => concurrency :
- async CUDA Opticks
- async CUDA memory pools [2]
- Robust Server (MC campaign):
- static flat VRAM
- backpressure, signal client retry
[1] https://developer.nvidia.com/dynamo-triton
[2] cudaMallocFromPoolAsync
Summary and Links
Opticks : state-of-the-art GPU ray traced optical simulation integrated with Geant4,
with automated geometry translation.
GPU-less OpticksClient + OpticksService in development,
bringing Opticks everywhere + improving GPU utilization.
- NVIDIA Ray Trace Performance continues rapid progress (2x each gen., every ~2 yrs)
- any simulation limited by optical photons can benefit from Opticks
- more photon limited -> more overall speedup (99% -> ~90x)