Opticks : Innovation in Optical Photon Simulation
Opticks : Innovation in Optical Photon Simulation via
state-of-the-art GPU Ray Tracing from NVIDIA® OptiX™
Open source, https://bitbucket.org/simoncblyth/opticks
Simon C Blyth, IHEP, CAS — Jan 2022, Hong Kong Workshop: Innovation in HEP Detectors & Computing
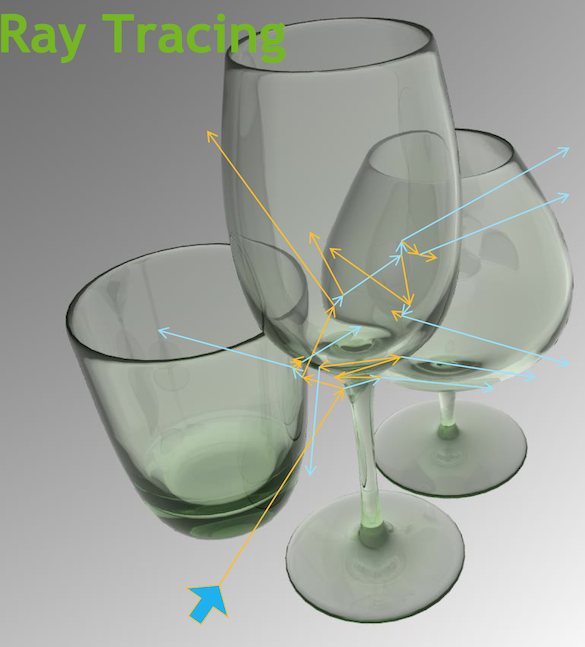
JUNO Optical Photon Simulation Problem...
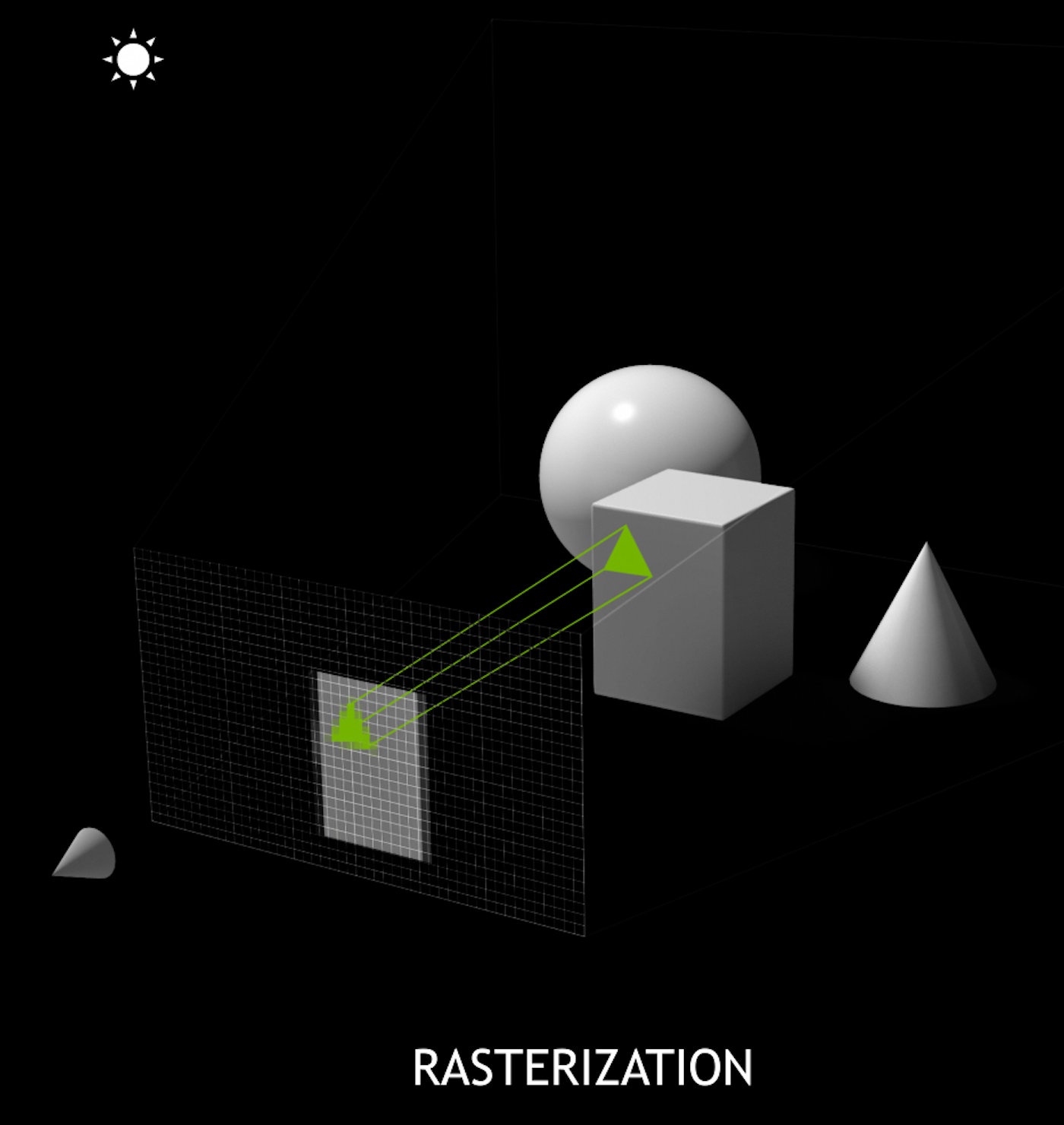
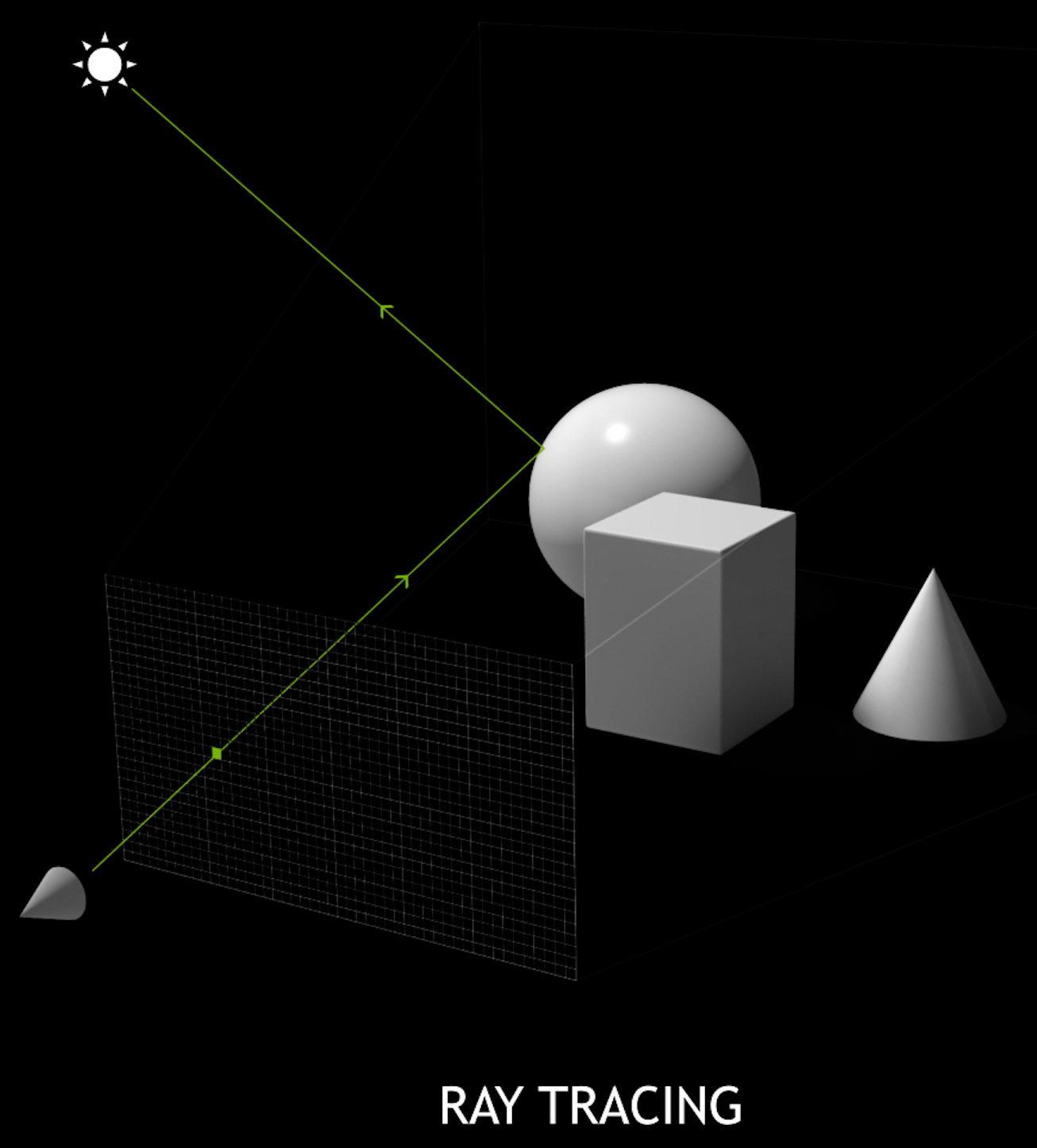
Optical Photon Simulation ≈ Ray Traced Image Rendering
Much in common : geometry, light sources, optical physics
- simulation : photon parameters at PMT detectors
- rendering : pixel values at image plane
- both limited by ray geometry intersection, aka ray tracing
Many Applications of ray tracing :
- advertising, design, architecture, films, games,...
- -> huge efforts to improve hw+sw over 30 yrs
Ray-tracing vs Rasterization
Path Tracing in Production 1
Path Tracing in Production 2
The Rendering Equation 1
The Rendering Equation 2
Samples per Pixel 1
Samples per Pixel 2
Optical Simulation : Computer Graphics vs Physics
| CG Rendering "Simulation" |
Particle Physics Simulation |
|---|
| simulates: image formation, vision |
simulates photons: generation, propagation, detection |
| (red, green, blue) |
wavelength range eg 400-700 nm |
| ignore polarization |
polarization vector propagated throughout |
| participating media: clouds,fog,fire [1] |
bulk scattering: Rayleigh, MIE |
| human exposure times |
nanosecond time scales |
| equilibrium assumption |
transient phenomena |
| ignores light speed, time |
arrival time crucial, speed of light : 30 cm/ns |
- handling of time is the crucial difference
Despite differences many techniques+hardware+software directly applicable to physics eg:
- GPU accelerated ray tracing (NVIDIA OptiX)
- GPU accelerated property interpolation via textures (NVIDIA CUDA)
- GPU acceleration structures (NVIDIA BVH)
Potentially Useful CG techniques for "billion photon simulations"
- irradiance caching, photon mapping, progressive photon mapping
[1] search for: "Volumetric Rendering Equation"
SIGGRAPH_2018_Announcing_Worlds_First_Ray_Tracing_GPU 2
Project Sol
Ampere : 2nd Generation RTX
- NVIDIA Ampere (2020):
- "...triple double over Turing (2018, 10 GigaRays/s)..."
- RT Core : ray trace dedicated GPU hardware
- NVIDIA GeForce RTX 3090
- 10,496 CUDA Cores, 28GB VRAM, USD 1499
- ray trace performance continues rapid improvement
NVIDIA Marbles At Night RTX Demo
GTC 2020, NVIDIA Marbles at Night RTX Demo
NVIDIA Marbles At Night RTX Demo 2
GTC 2020, NVIDIA Marbles at Night RTX Demo
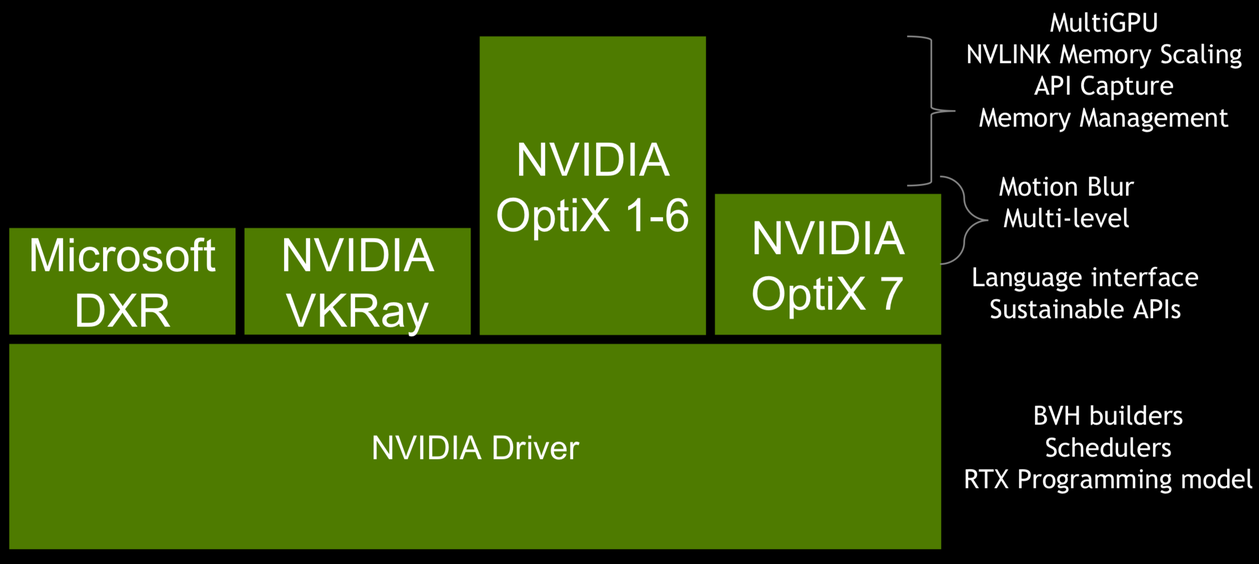
GPU Ray Tracing (RT) APIs Give Access to NVIDIA RTX
Three Similar Interfaces over same RTX tech:
NVIDIA OptiX (Linux, Windows) [2009]
- CUDA header only access to Driver functionality
- Most flexible API, OptiX, is used by Opticks
Vulkan RT (Linux, Windows) [final spec 2020]
- cross-vendor cross-platform RT
Microsoft DXR : DirectX 12 Ray Tracing (Windows) [2018]
- enhancing visual quality of realtime games
Metal Ray Tracing API (macOS) [introduced 2020[1]]
- Very different Integrated GPU : Apple Silicon M1 GPU
- BUT: similar API
[1] https://developer.apple.com/videos/play/wwdc2020/10012/
Spatial Index Acceleration Structure
NVIDIA OptiX 7 : Entirely new thin API (Introduced Aug 2019)
NVIDIA OptiX 6->7 : drastically slimmed down
- headers only (no library, just Driver)
- low-level CUDA-centric thin API (Vulkan-ized)
- Minimal host state, All host functions are thread-safe
- GPU launches : explicit, asynchronous (CUDA streams)
- near perfect scaling to 4 GPUs, for free
- Shared CPU/GPU geometry context
- GPU memory management
- Multi-GPU support
- Advantages
More control/flexibility over everything.
- Fully benefit from future GPUs
- Keep pace with state-of-the-art GPU ray tracing
- Disadvantages
Demands much more developer effort than OptiX 6
- Major re-implementation of Opticks required
LATEST: Opticks transition from 6->7 is ongoing
Geant4OpticksWorkflow
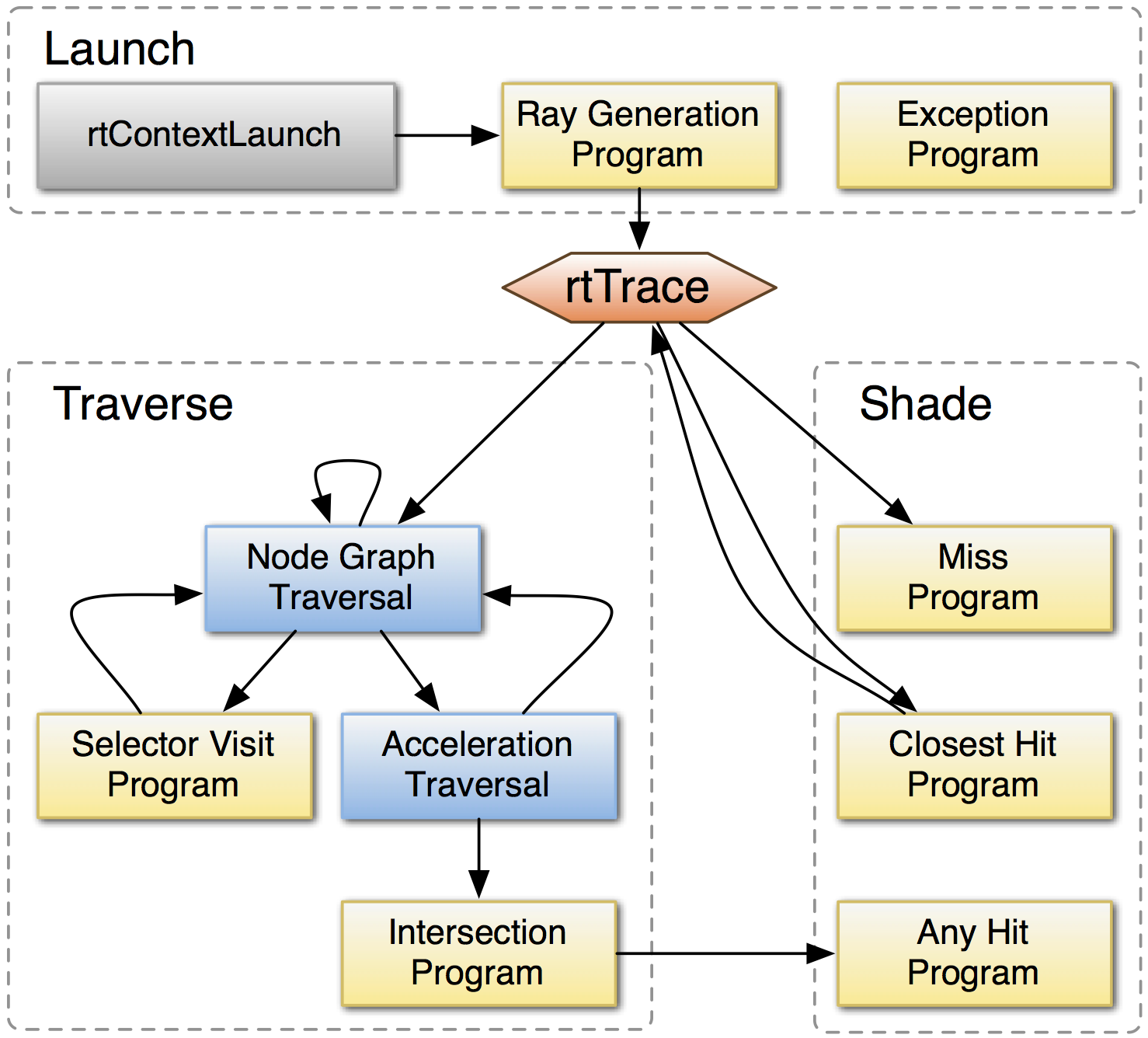
Opticks : Translates G4 Optical Physics to CUDA/OptiX
OptiX : single-ray programming model -> line-by-line translation
- CUDA Ports of Geant4 classes
- G4Cerenkov (only generation loop)
- G4Scintillation (only generation loop)
- G4OpAbsorption
- G4OpRayleigh
- G4OpBoundaryProcess (only a few surface types)
- Modify Cherenkov + Scintillation Processes
- collect genstep, copy to GPU for generation
- avoids copying millions of photons to GPU
- Scintillator Reemission
- fraction of bulk absorbed "reborn" within same thread
- wavelength generated by reemission texture lookup
- Opticks (OptiX/Thrust GPU interoperation)
- OptiX : upload gensteps
- Thrust : seeding, distribute genstep indices to photons
- OptiX : launch photon generation and propagation
- Thrust : pullback photons that hit PMTs
- Thrust : index photon step sequences (optional)
G4VSolid -> CUDA Intersect Functions for ~10 Primitives
- 3D parametric ray : ray(x,y,z;t) = rayOrigin + t * rayDirection
- implicit equation of primitive : f(x,y,z) = 0
- -> polynomial in t , roots: t > t_min -> intersection positions + surface normals
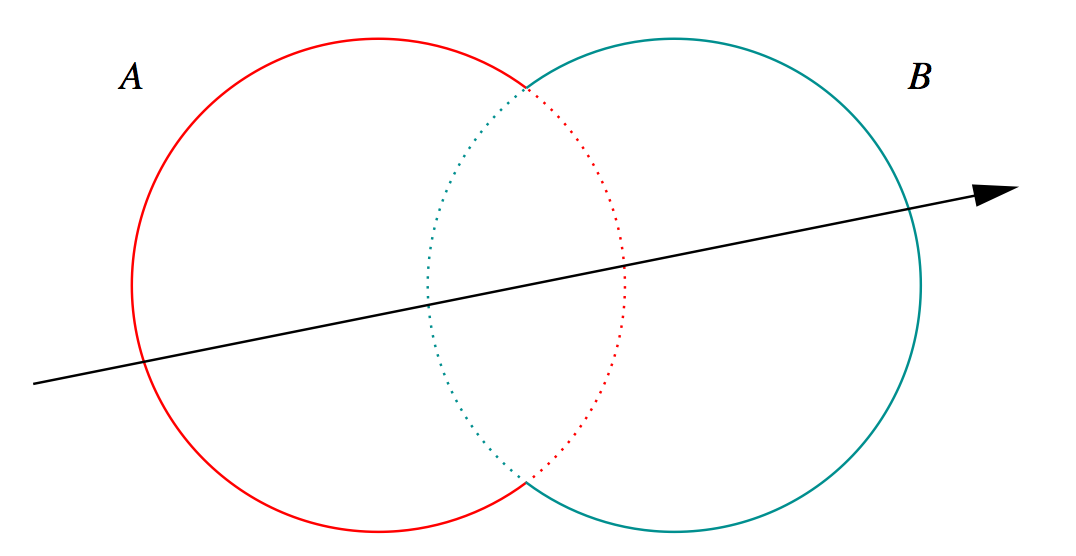
G4Boolean -> CUDA/OptiX Intersection Program Implementing CSG
Complete Binary Tree, pick between pairs of nearest intersects:
| UNION tA < tB |
Enter B |
Exit B |
Miss B |
|---|
| Enter A |
ReturnA |
LoopA |
ReturnA |
| Exit A |
ReturnA |
ReturnB |
ReturnA |
| Miss A |
ReturnB |
ReturnB |
ReturnMiss |
- Nearest hit intersect algorithm [1] avoids state
- sometimes Loop : advance t_min , re-intersect both
- classification shows if inside/outside
- Evaluative [2] implementation emulates recursion:
- recursion not allowed in OptiX intersect programs
- bit twiddle traversal of complete binary tree
- stacks of postorder slices and intersects
- Identical geometry to Geant4
- solving the same polynomials
- near perfect intersection match
- [1] Ray Tracing CSG Objects Using Single Hit Intersections, Andrew Kensler (2006)
- with corrections by author of XRT Raytracer http://xrt.wikidot.com/doc:csg
- [2] https://bitbucket.org/simoncblyth/opticks/src/tip/optixrap/cu/csg_intersect_boolean.h
- Similar to binary expression tree evaluation using postorder traverse.
Opticks : Translates G4 Geometry to GPU, Without Approximation
G4 Structure Tree -> Instance+Global Arrays -> OptiX
Group structure into repeated instances + global remainder:
- auto-identify repeated geometry with "progeny digests"
- JUNO : 9 distinct instances + 1 global
- instance transforms used in OptiX/OpenGL geometry
instancing -> huge memory savings for JUNO PMTs
Translation 1st Step : Geant4 -> Opticks/GGeo : 1->1 conversions
Structural volumes : G4PVPlacement ->
- GVolume
- JUNO: tree of ~300,000 GVolume
Solid shapes : G4VSolid ->
- GMesh (collected into GMeshLib)
arrays: vertices, indices
ref to NCSG
- NCSG
- tree of NNode (CSG constituents)
Material/surface properties as function of wavelength
- G4Material -> GMaterial
- G4Logical(Border/Skin)Surface -> GSurface
- adopts standard wavelength domain
- collected into GMaterialLib GSurfaceLib
Translation steered by X4 package
https://bitbucket.org/simoncblyth/opticks/src/master/extg4/X4PhysicalVolume.hh
Translation 2nd Step : Opticks/GGeo Instancing : "Factorizes" Geometry
- Structural volumes vs solid shapes
distinction for convenience only, distinction is movable
JUNO: ~300,000 GVolume : mostly small repeated groups (PMTs)
GGeo/GInstancer
- GVolume progeny digest : shapes+transforms -> subtree ident.
- find repeated digests, disqualifying repeats inside others
- label all nodes with repeat index, non-repeated remainder : 0
For each repeat+remainder create GMergedMesh:
- collecting transforms, identity -> instance arrays
- merged volumes+solids
- GMesh: concatenated arrays: triangles, indices
- GParts: concatenated arrays: CSG nodes + transforms
- transforms applied -> gets into instance frame
- Consolidation : structural volumes -> compound solid
GMergedMesh -> IAS+GAS
https://bitbucket.org/simoncblyth/opticks/src/master/ggeo/GInstancer.hh
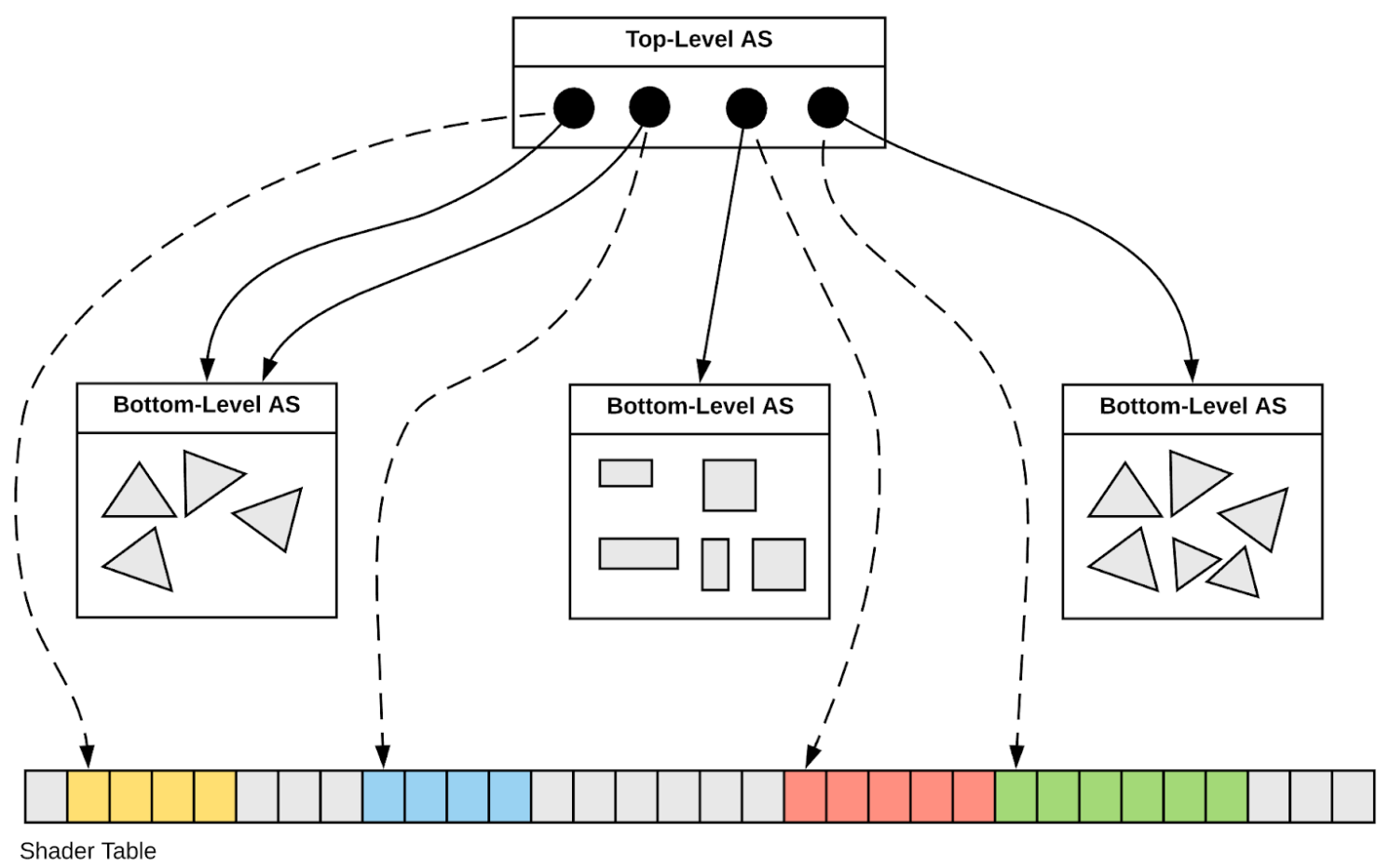
"CSGFoundry" : Shared CPU/GPU Geometry Model (OptiX pre-7 & 7)
- replaces geometry context dropped in OptiX 6->7
- array-based -> simple, inherent serialization + persisting
- entire geometry in 4 GPU allocations
- https://bitbucket.org/simoncblyth/opticks/src/master/CSG/
- CSGFoundry
- model, GPU upload
- csg_intersect_tree.h/csg_intersect_node.h/...
- simple headers common to pre-7/7/CPU-testing
- opticks/src/master/CSG_GGeo/
- Convert Opticks/GGeo -> CSGFoundry
- opticks/src/master/qudarap/
- Simulation excluding geometry, generation
- opticks/src/master/CSGOptiX/
- OptiX 7 + pre-7 geometry : depends on CSG, QUDARap
GAS : Geometry Acceleration Structure
IAS : Instance Acceleration Structure
CSG : Constructive Solid Geometry
Opticks Generality
Opticks Generality 2
cxr_overview_emm_t0_moi_-1_ALL.jpg
cxr_overview_emm_t0,_moi_-1.jpg
-e t0, : NOT 0 : 3084:sWorld : exclude global remainder volumes
cxr_overview_emm_image_grid_overview
- Comparison of ray traced render times of different geometry
- simple way to find issues, eg over complex CSG, overlarge BBox
sWaterTube_image_grid_cxr_view
- Same viewpoint inside JUNO Central Detector, vary included volumes
- ray trace performance very sensitive to geometry and its modelling => BVH structure
[Dec 2021] JUNO : OptiX 7 Ray Trace Times ~2M-pix : TITAN RTX
| idx |
-e |
time(s) |
relative |
enabled geometry description 3dbec4dc |
|---|
| 0 |
5, |
0.0004 |
0.0643 |
ONLY: 1:sStrutBallhead |
| 1 |
9, |
0.0004 |
0.0658 |
ONLY: 130:sPanel |
| 2 |
7, |
0.0005 |
0.0782 |
ONLY: 1:base_steel |
| 3 |
8, |
0.0006 |
0.0966 |
ONLY: 1:uni_acrylic1 |
| 4 |
6, |
0.0006 |
0.1009 |
ONLY: 1:uni1 |
| 5 |
1, |
0.0009 |
0.1476 |
ONLY: 5:PMT_3inch_pmt_solid FAST cf 20in |
| 6 |
4, |
0.0015 |
0.2386 |
ONLY: 4:mask_PMT_20inch_vetosMask |
| 7 |
3, |
0.0033 |
0.5373 |
ONLY: 5:HamamatsuR12860sMask SLOW cf 3in |
| 8 |
0, |
0.0040 |
0.6556 |
ONLY: 3084:sWorld |
| 9 |
2, |
0.0040 |
0.6627 |
ONLY: 5:NNVTMCPPMTsMask SLOW cf 3in |
| 10 |
t4, |
0.0050 |
0.8307 |
EXCL: 4:mask_PMT_20inch_vetosMask |
| 11 |
t2, |
0.0051 |
0.8391 |
EXCL: 5:NNVTMCPPMTsMask |
| 12 |
t3, |
0.0052 |
0.8514 |
EXCL: 5:HamamatsuR12860sMask |
| 13 |
t6, |
0.0053 |
0.8799 |
EXCL: 1:uni1 |
| 14 |
t7, |
0.0054 |
0.8809 |
EXCL: 1:base_steel |
| 15 |
t0 |
0.0054 |
0.8843 |
ALL |
| 16 |
t5, |
0.0054 |
0.8843 |
EXCL: 1:sStrutBallhead |
| 17 |
t9, |
0.0054 |
0.8855 |
EXCL: 130:sPanel |
| 18 |
t1, |
0.0054 |
0.8860 |
EXCL: 5:PMT_3inch_pmt_solid |
| 19 |
t8, |
0.0055 |
0.9013 |
EXCL: 1:uni_acrylic1 |
| 20 |
t0, |
0.0059 |
0.9753 |
EXCL: 3084:sWorld |
| 21 |
1,2,3,4 |
0.0061 |
1.0000 |
ONLY PMT |
| 22 |
t8,0 |
0.0062 |
1.0217 |
EXCL: 1:uni_acrylic1 3084:sWorld |
Validation of Opticks Simulation by Comparison with Geant4
Bi-simulations of all JUNO solids, with millions of photons
- mis-aligned histories
- mostly < 0.25%, < 0.50% for largest solids
- deviant photons within matched history
- < 0.05% (500/1M)
Primary sources of problems
- grazing incidence, edge skimmers
- incidence at constituent solid boundaries
Primary cause : float vs double
Geant4 uses double everywhere, Opticks only sparingly (observed double costing 10x slowdown with RTX)
Conclude
- neatly oriented photons more prone to issues than realistic ones
- perfect "technical" matching not feasible
- instead shift validation to more realistic full detector "calibration" situation
scan-pf-check-GUI-TO-SC-BT5-SD
scan-pf-check-GUI-TO-BT5-SD
scan-pf-1_Opticks_vs_Geant4 2
| JUNO analytic, 400M photons from center |
Speedup |
|---|
| Geant4 Extrap. |
95,600 s (26 hrs) |
|
| Opticks RTX ON (i) |
58 s |
1650x |
scan-pf-1_Opticks_Speedup 2
| JUNO analytic, 400M photons from center |
Speedup |
|---|
| Opticks RTX ON (i) |
58s |
1650x |
| Opticks RTX OFF (i) |
275s |
350x |
| Geant4 Extrap. |
95,600s (26 hrs) |
|
Useful Speedup > 1500x : But Why Not Giga Rays/s ? (1 Photon ~10 Rays)
- NVIDIA claim : 10 Giga Rays/s with RT Core
- -> 1 Billion photons per second
- RT cores : built-in triangle intersect + 1-level of instancing
- flatten scene model to avoid SM<->RT roundtrips ?
OptiX Performance Tools and Tricks, David Hart, NVIDIA
https://developer.nvidia.com/siggraph/2019/video/sig915-vid
geocache_360