LZ-Opticks-NVIDIA OptiX 6->7 : Notes
PROGRESS : OptiXTest -> CSG + CSGOptiX, added CSG_GGeo
- CSG : CSGFoundry model, simple intersect headers : CPU testable
- CSG_GGeo : loads Opticks/GGeo, converts to CSG
- CSGOptiX : OptiX 7 + pre-7 renders of CSGFoundry geometry
NEXT STEPS:
- investigate 2 slow solids in JUNO geometry, try different instance criteria, modelling
- systematic comparison of render times with 6 and 7 : stack size tuning
- reduce CSGOptiX code ~duplicated between pre-7:Six.cc, 7:SBT.cc : unify code in common
- bring over event handling (photon generation + propagation)
- pull out simple headers common to: pre-7, 7, CPU testing (minimize code difference between envs)
- trickery/mocking needed for CURAND on CPU? (templating?)
- integrate packages with Opticks
LONGTERM POSSIBILITY : Populate CSGFoundry model direct from Geant4 geometry ? [Disruptive]
Simon C Blyth, May 18, 2021
New "Foundry" Model : Shared CPU/GPU Geometry Context
- replaces geometry context dropped in OptiX 6->7
- array-based -> simple, inherent serialization + persisting
- entire geometry in 4 GPU allocations
Simple intersect headers, common CPU/GPU types
- use with : pre-7, 7 + testing on CPU
- https://github.com/simoncblyth/CSG "Foundry" model
- csg_intersect_tree.h/csg_intersect_node.h/...
- simple headers common to pre-7/7/CPU-testing
- https://github.com/simoncblyth/CSG_GGeo
- Convert Opticks/GGeo -> CSGFoundry
- https://github.com/simoncblyth/CSGOptiX
- OptiX 7 + pre-7 rendering
GAS : Geometry Acceleration Structure
IAS : Instance Acceleration Structure
CSG : Constructive Solid Geometry
OptiX 7 + pre-7 intersecting same CSGFoundry geometry
- https://github.com/simoncblyth/CSGOptiX
OptiX7Test.cu
150 extern "C" __global__ void __intersection__is()
151 {
152 HitGroupData* hg = (HitGroupData*)optixGetSbtDataPointer();
153 int numNode = hg->numNode ;
154 int nodeOffset = hg->nodeOffset ;
155
156 const CSGNode* node = params.node + nodeOffset ;
157 const float4* plan = params.plan ;
158 const qat4* itra = params.itra ;
159
160 const float t_min = optixGetRayTmin() ;
161 const float3 ray_origin = optixGetObjectRayOrigin();
162 const float3 ray_direction = optixGetObjectRayDirection();
163
164 float4 isect ;
165 if(intersect_prim(isect, numNode, node, plan, itra,
t_min , ray_origin, ray_direction ))
166 {
...
175 optixReportIntersection( isect.w, hitKind, a0, a1, a2, a3 );
176 }
177 }
Minimize code split : 7, pre-7, CPU testing : same intersect_prim
CSG_GGeo : loads Opticks/GGeo, converts to CSGFoundry model
- https://github.com/simoncblyth/CSG_GGeo
..
11 int main(int argc, char** argv)
12 {
13 OPTICKS_LOG(argc, argv);
14
15 Opticks ok(argc, argv);
16 ok.configure();
17
18 GGeo* ggeo = GGeo::Load(&ok);
19
20 CSGFoundry foundry ;
21 CSG_GGeo_Convert conv(&foundry, ggeo) ;
22 conv.convert();
...
39 foundry.write(cfbase, rel );
40
41 CSGFoundry* fd = CSGFoundry::Load(cfbase, rel);
42 assert( 0 == CSGFoundry::Compare(&foundry, fd ) );
43
44 return 0 ;
45 }
- GGeo::Load geocache identified by OPTICKS_KEY envvar
- LONGTERM: direct Geant4 -> CSG ? disruptive
- disruptive but allows big code reductions in NPY/NNode
[9]cxr_i0_t8,_-1 : EXCLUDE SLOWEST
Current JUNO Geometry : Auto-Factorized by "progeny digest"
| ridx |
plc |
prim |
component |
note |
|---|
| 0 |
1 |
3084 |
3084:sWorld |
non-repeated remainder |
| 1 |
25600 |
5 |
5:PMT_3inch_pmt_solid |
4 types of PMT |
| 2 |
12612 |
5 |
5:NNVTMCPPMTsMask |
| 3 |
5000 |
5 |
5:HamamatsuR12860sMask |
| 4 |
2400 |
5 |
5:mask_PMT_20inch_vetosMask |
| 5 |
590 |
1 |
1:sStrutBallhead |
4 parts of same
assembly, BUT not
grouped as siblings
(not parent-child) |
| 6 |
590 |
1 |
1:uni1 |
| 7 |
590 |
1 |
1:base_steel |
| 8 |
590 |
1 |
1:uni_acrylic3 |
| 9 |
504 |
130 |
130:sPanel |
repeated parts of TT |
- ridx:0 "remainder" Prim
- Prim that did not pass instancing criteria, on number of repeats + complexity
- TODO: tune criteria to instance more, reducing remainder Prim (Expect: 3084->~ 84)
- ridx:1,2,3,4
- four types of PMT, all with 5 Prim
- ridx:5,6,7,8
- same 590x assembly but not grouped together : as siblings (not parent-child like PMTs)
- TODO: implement instancing of siblings, combining 4 -> 1
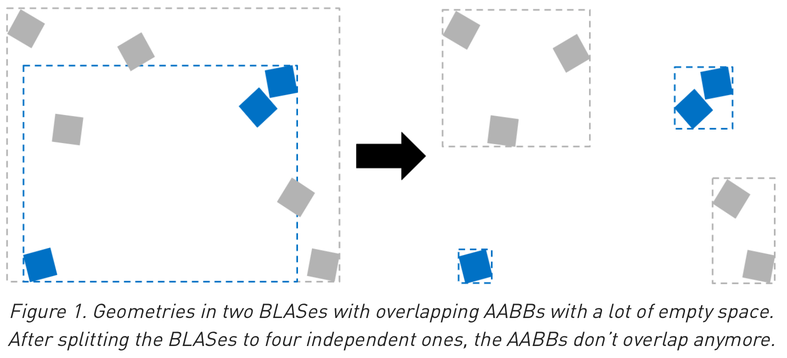
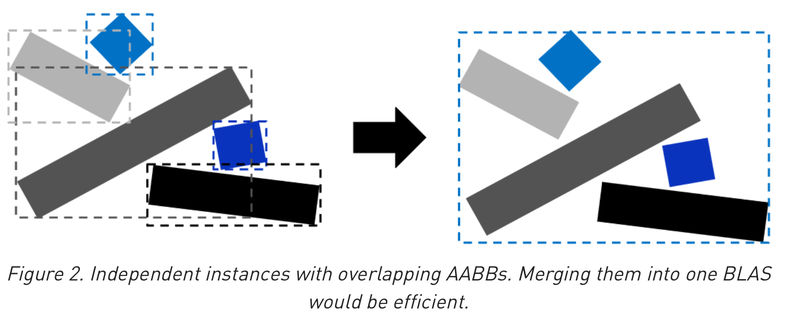
Increasing instancing : reduces memory for geometry -> improved performance
JUNO OptiX 7 : "Foundry" Geometry Scan
JUNO Geometry : OptiX 7 Ray Trace Times ~2M pixels : TITAN RTX
| idx |
-e |
time(s) |
relative |
enabled geometry description |
|---|
| 0 |
9, |
0.0017 |
0.1702 |
ONLY: 130:sPanel |
| 1 |
7, |
0.0017 |
0.1714 |
ONLY: 1:base_steel |
| 2 |
6, |
0.0019 |
0.1923 |
ONLY: 1:uni1 |
| 3 |
5, |
0.0027 |
0.2780 |
ONLY: 1:sStrutBallhead |
| 4 |
4, |
0.0032 |
0.3268 |
ONLY: 5:mask_PMT_20inch_vetosMask |
| 5 |
1, |
0.0032 |
0.3287 |
ONLY: 5:PMT_3inch_pmt_solid |
| 6 |
2, |
0.0055 |
0.5669 |
ONLY: 5:NNVTMCPPMTsMask |
| 7 |
3, |
0.0074 |
0.7582 |
ONLY: 5:HamamatsuR12860sMask |
| 8 |
1,2,3,4 |
0.0097 |
1.0000 |
ONLY PMT |
| 9 |
t8,0 |
0.0099 |
1.0179 |
EXCL: 1:uni_acrylic3 3084:sWorld |
| 10 |
0, |
0.1171 |
12.0293 |
ONLY: 3084:sWorld |
| 11 |
t8, |
0.1186 |
12.1769 |
EXCL: 1:uni_acrylic3 |
| 12 |
t0, |
0.5278 |
54.2066 |
EXCL: 3084:sWorld |
| 13 |
8, |
0.5310 |
54.5298 |
ONLY: 1:uni_acrylic3 |
| 14 |
t3, |
0.6017 |
61.7954 |
EXCL: 5:HamamatsuR12860sMask |
| 15 |
t2, |
0.6043 |
62.0620 |
EXCL: 5:NNVTMCPPMTsMask |
| 16 |
t5, |
0.6171 |
63.3787 |
EXCL: 1:sStrutBallhead |
| 17 |
t6, |
0.6196 |
63.6301 |
EXCL: 1:uni1 |
| 18 |
t7, |
0.6226 |
63.9458 |
EXCL: 1:base_steel |
| 19 |
t0 |
0.6240 |
64.0879 |
3084:sWorld |
| 20 |
t4, |
0.6243 |
64.1169 |
EXCL: 5:mask_PMT_20inch_vetosMask |
| 21 |
t9, |
0.6335 |
65.0636 |
EXCL: 130:sPanel |
| 22 |
t1, |
0.6391 |
65.6384 |
EXCL: 5:PMT_3inch_pmt_solid |
JUNO ALL PMTs : 2M ray traced pixels in 0.0097 s : NVIDIA TITAN RTX, NVIDIA OptiX 7.0.0, Opticks
[8]cxr_i0_1,2,3,4_-1 ALL PMTs
/env/presentation/cxr/cxr_overview/cxr_i0_1,2,3,4_-1.jpg 1280px_720px
"Flat" look is a bug
Was only rendering the last Prim for GAS after the 1st
CAUSE: using globalPrimIdx for SBTIndexOffset : needs to be GAS local
[10]cxr_i0_0,_-1 ONLY GLOBAL "REMAINDER"
/env/presentation/cxr/cxr_overview/cxr_i0_0,_-1.jpg 1280px_720px
3084 "remainder" non-instance volumes : is far too many
Looks to be obvious repetitions missed by the auto-instancer
[9]cxr_i0_t8,_-1 EXCLUDE SLOWEST 1
/CSG_GGeo/cvd1/70000/cxr_overview/cam_0_tmin_0.4/cxr_overview_emm_t8,_moi_-1.jpg 1280px_720px
Flipping between this and the next, shows the missing Prim bug effect
[9]cxr_i0_t8,_-1 EXCLUDE SLOWEST 2
/env/presentation/cxr/cxr_overview/cxr_i0_t8,_-1.jpg 1280px_720px
Flipping between this and the prev, shows the missing Prim bug effect
cxr_view_0
Inside View with only global remainder geometry
Same viewpoint in OptiX 5,6 and 7
- launch time (s) at bottom left
- OptiX 5 : NVIDIA Geforce 750M (2013 Macbook Pro)
- OptiX 6, 7 : NVIDIA TITAN RTX
cxr_view_1
/CSG_GGeo/cvd0/50001/cxr_view/cam_0_1,/cxr_view_sWaterTube.jpg 640px_360px 640px_0px
/CSG_GGeo/cvd1/60500/cxr_view/cam_0_1,/cxr_view_sWaterTube.jpg 640px_360px 0px_360px
/CSG_GGeo/cvd1/70000/cxr_view/cam_0_1,/cxr_view_sWaterTube.jpg 640px_360px 640px_360px
- OptiX 7 to bottom right, with grey background
- missing Prim bug visible, just get the cylinder Prim
cxr_solid_r1p
These renders use ONE_PRIM_SOLID envvar with the Converter
to add CSGFoundry solids containing a single Prim only.
Example solid names: r1p0 r1p1 r1p2 r1p3 r1p4
Then can plot them all using:
./cxr_solid.sh r1p
The argument selects 5 single prim solids and puts
them into an IAS with Y-translations.
cxr_view_2
/CSG_GGeo/cvd0/50001/cxr_view/cam_0_2,/cxr_view_sWaterTube.jpg 640px_360px 640px_0px
/CSG_GGeo/cvd1/60500/cxr_view/cam_0_2,/cxr_view_sWaterTube.jpg 640px_360px 0px_360px
/CSG_GGeo/cvd1/70000/cxr_view/cam_0_2,/cxr_view_sWaterTube.jpg 640px_360px 640px_360px
OptiX 5,6,7
Last Prim SBT bug apparent with 7
cxr_solid_r2p
/CSG_GGeo/cvd0/50001/cxr_solid/cam_1/cxr_solid_r2p.jpg 640px_360px 0px_360px
/CSG_GGeo/cvd1/70000/cxr_solid/cam_1/cxr_solid_r2p.jpg 640px_360px 640px_360px
Five of the debug single Prim solids selected with:
./cxr_solid.sh r2p
cxr_view_9
/CSG_GGeo/cvd0/50001/cxr_view/cam_0_9,/cxr_view_sWaterTube.jpg 640px_360px 640px_0px
/CSG_GGeo/cvd1/60500/cxr_view/cam_0_9,/cxr_view_sWaterTube.jpg 640px_360px 0px_360px
/CSG_GGeo/cvd1/70000/cxr_view/cam_0_9,/cxr_view_sWaterTube.jpg 640px_360px 640px_360px
| ridx |
plc |
prim |
component |
note |
|---|
| 9 |
504 |
130 |
130:sPanel |
repeated parts of TT |
Only last of 130 Prim appears (OptiX 7), again due to globalPrimIdx bug
cxr_view_8
/CSG_GGeo/cvd0/50001/cxr_view/cam_0_8,/cxr_view_sWaterTube.jpg 640px_360px 640px_0px
/CSG_GGeo/cvd1/60500/cxr_view/cam_0_8,/cxr_view_sWaterTube.jpg 640px_360px 0px_360px
/CSG_GGeo/cvd1/70000/cxr_view/cam_0_8,/cxr_view_sWaterTube.jpg 640px_360px 640px_360px
Blank render for solid 8 in OptiX 5,6 and 7
[13]lLowerChimney_phys__t5,__00000
Solid 8 "1:uni_acrylic3" is the "plunger" cup that holds the acrylic 35m diameter sphere
[12]lLowerChimney_phys__t0,__00000
Currently the shape does a CSG subtraction with the huge sphere
[11]lLowerChimney_phys__8,__00000
| ridx |
plc |
prim |
component |
note |
|---|
| 8 |
590 |
1 |
1:uni_acrylic3 |
|
590 of these all around the 35m diameter sphere
[10]lLowerChimney_phys__t8,__00000
Has complicated CSG insides too, subtracting the 8 column "greek temple"
G4Boolean -> CUDA/OptiX Intersection Program Implementing CSG
Complete Binary Tree, pick between pairs of nearest intersects:
| UNION tA < tB |
Enter B |
Exit B |
Miss B |
|---|
| Enter A |
ReturnA |
LoopA |
ReturnA |
| Exit A |
ReturnA |
ReturnB |
ReturnA |
| Miss A |
ReturnB |
ReturnB |
ReturnMiss |
- Nearest hit intersect algorithm [1] avoids state
- sometimes Loop : advance t_min , re-intersect both
- classification shows if inside/outside
- Evaluative [2] implementation emulates recursion:
- recursion not allowed in OptiX intersect programs
- bit twiddle traversal of complete binary tree
- stacks of postorder slices and intersects
- Identical geometry to Geant4
- solving the same polynomials
- near perfect intersection match
- [1] Ray Tracing CSG Objects Using Single Hit Intersections, Andrew Kensler (2006)
- with corrections by author of XRT Raytracer http://xrt.wikidot.com/doc:csg
- [2] https://bitbucket.org/simoncblyth/opticks/src/tip/optixrap/cu/csg_intersect_boolean.h
- Similar to binary expression tree evaluation using postorder traverse.
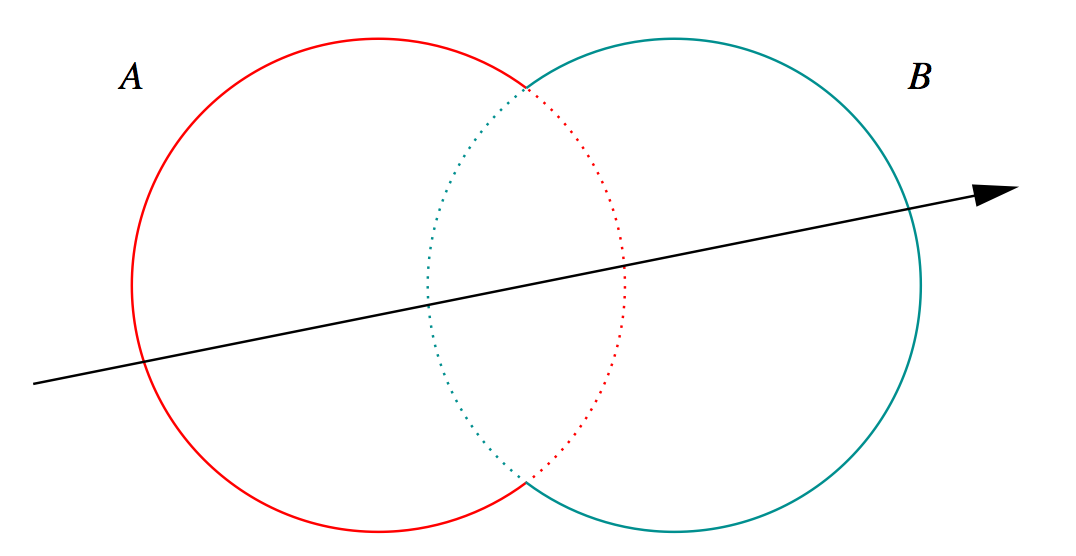
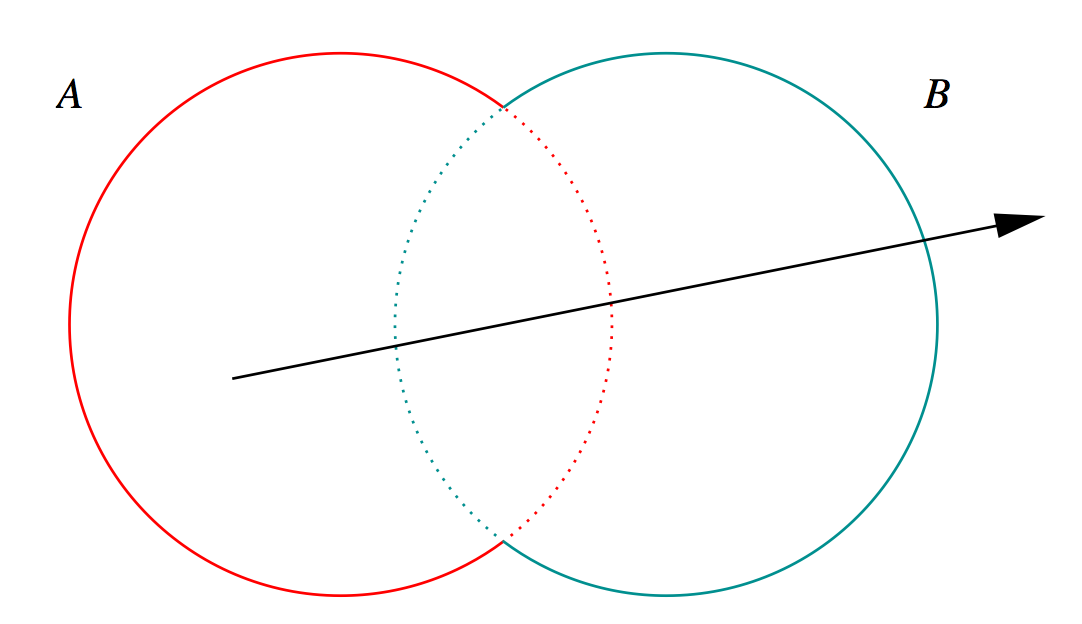
Constructive Solid Geometry (CSG) : Shapes defined "by construction"
Simple by construction definition, implicit geometry.
- A, B implicit primitive solids
- A + B : union (OR)
- A * B : intersection (AND)
- A - B : difference (AND NOT)
- !B : complement (NOT) (inside <-> outside)
CSG expressions
- non-unique: A - B == A * !B
- represented by binary tree, primitives at leaves
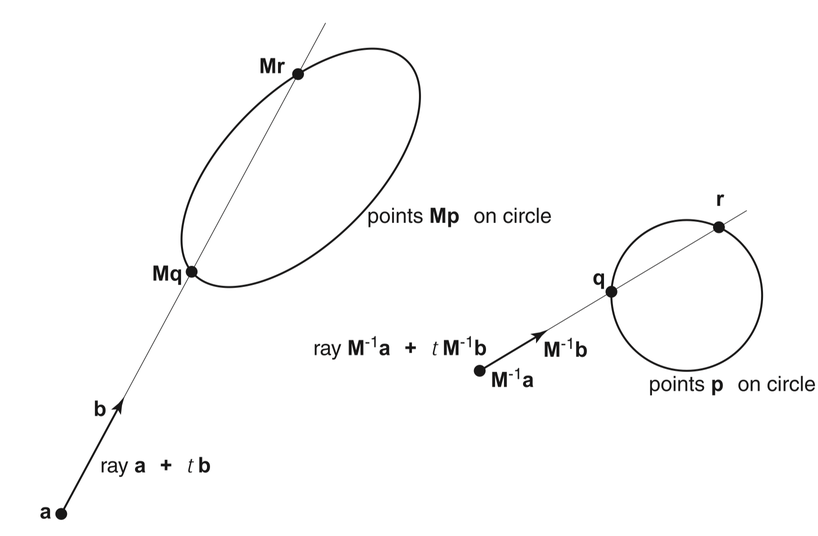
3D Parametric Ray : ray(t) = r0 + t rDir
Ray Geometry Intersection
- primitive : find t roots of implicit eqn
- composite : pick primitive intersect, depending on CSG tree
How to pick exactly ?
CSG : Which primitive intersect to pick ?
Classical Roth diagram approach
- find all ray/primitive intersects
- recursively combine inside intervals using CSG operator
- works from leaves upwards
Computational requirements:
- find all intersects, store them, order them
- recursive traverse
BUT : High performance on GPU requires:
- massive parallelism -> more the merrier
- low register usage -> keep it simple
- small stack size -> avoid recursion
Classical approach not appropriate on GPU
CSG Complete Binary Tree Serialization -> simplifies GPU side
Geant4 solid -> CSG binary tree (leaf primitives, non-leaf operators, 4x4 transforms on any node)
Serialize to complete binary tree buffer:
- no need to deserialize, no child/parent pointers
- bit twiddling navigation avoids recursion
- simple approach profits from small size of binary trees
- BUT: very inefficient when unbalanced
Height 3 complete binary tree with level order indices:
depth elevation
1 0 3
10 11 1 2
100 101 110 111 2 1
1000 1001 1010 1011 1100 1101 1110 1111 3 0
postorder_next(i,elevation) = i & 1 ? i >> 1 : (i << elevation) + (1 << elevation) ; // from pattern of bits
Postorder tree traverse visits all nodes, starting from leftmost, such that children
are visited prior to their parents.
Evaluative CSG intersection Pseudocode : recursion emulated
fullTree = PACK( 1 << height, 1 >> 1 ) // leftmost, parent_of_root(=0)
tranche.push(fullTree, ray.tmin)
while (!tranche.empty) // stack of begin/end indices
{
begin, end, tmin <- tranche.pop ; node <- begin ;
while( node != end ) // over tranche of postorder traversal
{
elevation = height - TREE_DEPTH(node) ;
if(is_primitive(node)){ isect <- intersect_primitive(node, tmin) ; csg.push(isect) }
else{
i_left, i_right = csg.pop, csg.pop // csg stack of intersect normals, t
l_state = CLASSIFY(i_left, ray.direction, tmin)
r_state = CLASSIFY(i_right, ray.direction, tmin)
action = LUT(operator(node), leftIsCloser)(l_state, r_state)
if( action is ReturnLeft/Right) csg.push(i_left or i_right)
else if( action is LoopLeft/Right)
{
left = 2*node ; right = 2*node + 1 ;
endTranche = PACK( node, end );
leftTranche = PACK( left << (elevation-1), right << (elevation-1) )
rightTranche = PACK( right << (elevation-1), node )
loopTranche = action ? leftTranche : rightTranche
tranche.push(endTranche, tmin)
tranche.push(loopTranche, tminAdvanced ) // subtree re-traversal with changed tmin
break ; // to next tranche
}
}
node <- postorder_next(node, elevation) // bit twiddling postorder
}
}
isect = csg.pop(); // winning intersect
https://bitbucket.org/simoncblyth/opticks/src/tip/optixrap/cu/csg_intersect_boolean.h
CSG Deep Tree : Positivize tree using De Morgan's laws
1st step to allow balancing : Positivize : remove CSG difference di operators
... ...
un cy
un cy
un cy
un cy
un cy
di cy
cy cy
... ...
un cy
un cy
un cy
un cy
un cy
in cy
cy !cy
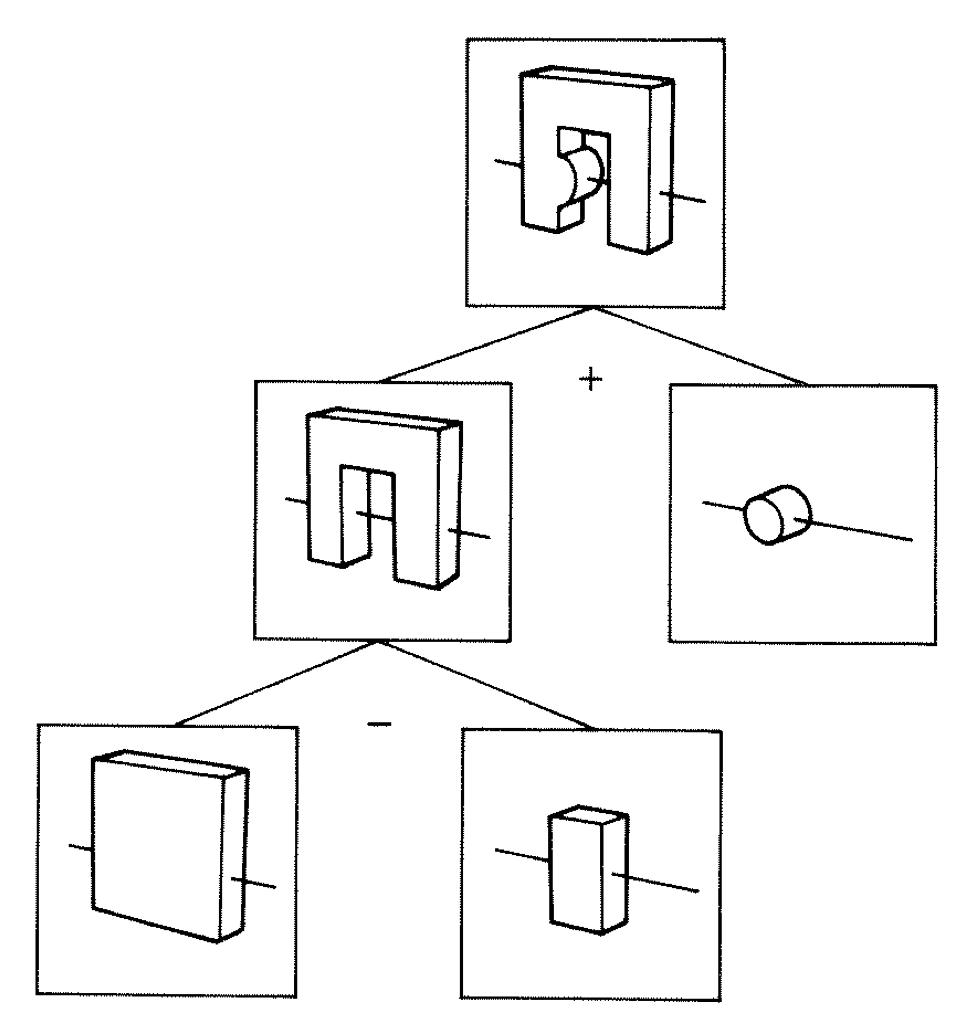
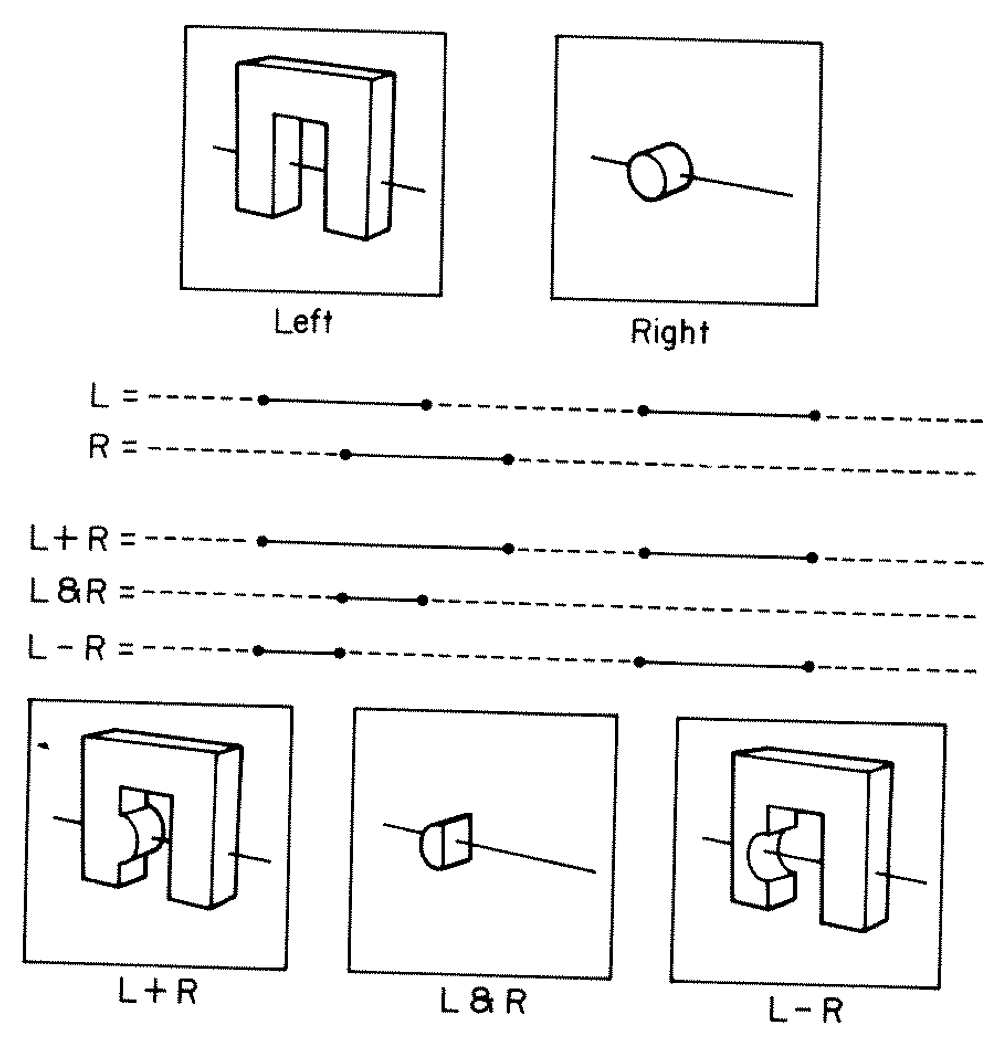
CSG Examples
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}