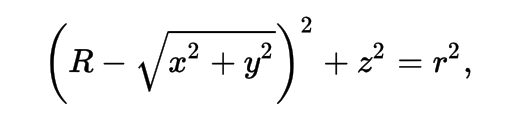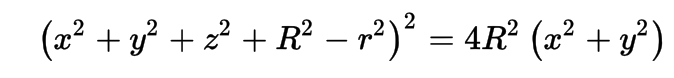LZ-Opticks-NVIDIA OptiX 6->7 : Notes
Progress
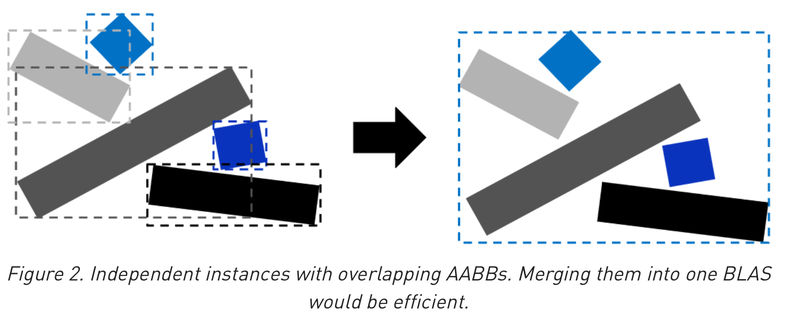
- GAS:BI:AABB 1NN vs 11N
- 1NN clips to smallest AABB from all BI -> move to 11N : all AABB in single BI
- Generalized Shape handling
- Node struct with four quads
- Geometry Identity
NEXT STEPS:
- bring in the rest of the primitives : not all plane sailing (convexpolyhedron, trapezoid)
- needs Prim to offset into array of planes
- CSG : intersect_tree, also needs Prim:
- offsets into array of CSG transforms + provide number of Node in tree
- Interface with Opticks : GMergedMesh -> Node,Prim,Plan,Tran -> SBT records
- performance tests with full geometries, try different approaches:
- For "global" non-repeated : one big remainder GAS ? Or split up into many GAS ?
- Reference all GAS (repeats and singles) from one IAS, or multi-IAS ?
Simon C Blyth, March 15 2021
GAS:BI:AABB 1NN vs 11N for 20 concentric spheres
env.sh
tmin=1.0
geometry=sphere
eye=-0.5,-0.5,0.5
gas_bi_aabb=0 # 0:1NN 1:11N
layers=20
Shape generalization with : Node, quad, (Prim)
146 extern "C" __global__ void __intersection__is()
147 {
148 HitGroupData* hg =
reinterpret_cast<HitGroupData*>(optixGetSbtDataPointer());
149 const Node* node = hg->node ;
150
151 const float3 ray_origin = optixGetObjectRayOrigin();
152 const float3 ray_direction = optixGetObjectRayDirection();
153 const float t_min = optixGetRayTmin() ;
154
155 float4 isect ;
156 bool valid_isect =
intersect_node(isect, node, t_min, ray_origin, ray_direction);
157
158 if(valid_isect)
159 {
160 const unsigned hitKind = 0u ; // user hit kind
161 unsigned a0, a1, a2, a3; // attribute registers
162
163 a0 = float_as_uint( isect.x );
164 a1 = float_as_uint( isect.y );
165 a2 = float_as_uint( isect.z );
166 a3 = float_as_uint( isect.w ) ;
167
168 optixReportIntersection( isect.w, hitKind, a0, a1, a2, a3 );
169 }
170 }
Plan : generalization to trees of Node using Prim
- Prim: num_node + tran, plan offsets
intersect_node switch statement
129 INTERSECT_FUNC
130 bool intersect_node( float4& isect, const Node* node, const float t_min , const float3& ray_origin, const float3& ray_dir )
131 {
132 const unsigned typecode = node->typecode() ;
133 bool valid_isect = false ;
134 switch(typecode)
135 {
136 case CSG_SPHERE: valid_isect = intersect_node_sphere( isect, node->q0, t_min, ray_origin, ray_dir ) ; break ;
137 case CSG_ZSPHERE: valid_isect = intersect_node_zsphere( isect, node->q0, node->q1, t_min, ray_origin, ray_dir ) ; break ;
138 }
139 return valid_isect ;
140 }
Split off intersection maths into intersect_node.h -> allows testing on CPU with intersect_node.cc
https://github.com/simoncblyth/OptiXTest/blob/main/intersect_node.h
https://github.com/simoncblyth/OptiXTest/blob/main/intersect_node.cc
Geometry Identifier : single 32-bit unsigned encoding indices: (ias,instance,gas,prim) ?
172 extern "C" __global__ void __closesthit__ch()
173 {
174 const float3 isect_normal =
175 make_float3(
176 uint_as_float( optixGetAttribute_0() ),
177 uint_as_float( optixGetAttribute_1() ),
178 uint_as_float( optixGetAttribute_2() )
179 );
180
181 const float t = uint_as_float( optixGetAttribute_3() ) ;
182
183 unsigned instance_id = optixGetInstanceId() ; // packed (instance_idx,gas_idx)
184 unsigned prim_id = 1u + optixGetPrimitiveIndex() ;
185 unsigned identity =
(( prim_id & 0xff ) << 24 ) | ( instance_id & 0x00ffffff ) ;
186
187 float3 normal = normalize(
optixTransformNormalFromObjectToWorldSpace( isect_normal )
) * 0.5f + 0.5f ;
188
189 const float3 world_origin = optixGetWorldRayOrigin() ;
190 const float3 world_direction = optixGetWorldRayDirection() ;
191 const float3 world_position = world_origin + t*world_direction ;
192
193 setPayload( normal, t, world_position, identity );
194 }
https://github.com/simoncblyth/OptiXTest/blob/main/OptiX7Test.cu
Intersect Identity : Pack (ins_idx, gas_idx) into 14+10=24 bit InstanceId
pack (instance_idx, gas_idx) into instance_id
29 struct InstanceId
30 {
31 enum { ins_bits = 14, gas_bits = 10 } ;
32
33 static constexpr unsigned ins_mask = ( 1 << ins_bits ) - 1 ;
34 static constexpr unsigned gas_mask = ( 1 << gas_bits ) - 1 ;
35
36 static unsigned Encode(unsigned ins_idx, unsigned gas_idx );
37 static void Decode(unsigned& ins_idx, unsigned& gas_idx,
const unsigned identity );
38 };
39
40 inline unsigned InstanceId::Encode(
unsigned ins_idx, unsigned gas_idx )
41 {
42 assert( ins_idx < ins_mask );
43 assert( gas_idx < gas_mask );
44 unsigned identity =
(( 1 + ins_idx ) << gas_bits ) | (( 1 + gas_idx ) << 0 ) ;
45 return identity ;
46 }
- 10 gas bits (max 0x3ff = 1023) is probably enough
- 14 instance bits (max 0x3fff : 16383) : not enough instances for JUNO
- TODO: move to identity encoding via bias to optixGetPrimitiveIndex()
- Much easier to pack into 30-bits rather than 24-bits
https://github.com/simoncblyth/OptiXTest/blob/main/InstanceId.h
Detector Geometry in Opticks
Detector Geometry in Opticks :
GPU Optical Simulation with NVIDIA® OptiX™
Open source, https://bitbucket.org/simoncblyth/opticks
Simon C Blyth, IHEP, CAS — Compute Accelerator Forum Meeting, March 10 2021, Virtual
Outline

- Introduction
- JUNO Optical Photon Simulation Problem...
- NVIDIA Marbles at Night : RTX Demo ; NVIDIA Ampere : 2nd Generation RTX
- GPU Ray Tracing APIs Converging
- RTX Execution Pipeline : Common to DirectX RT, VulkanRT, NVIDIA OptiX
- Spatial Index Acceleration Structure
- Two-Level Hierarchy : Instance transforms (TLAS) over Geometry (BLAS)
- Opticks : Structural Geometry
- Geant4 + Opticks Hybrid Workflow
- NPY Serialization : Fundamental to Opticks Geometry Model ; NumPy Example
- Translation 1st Step : Geant4 -> Opticks/GGeo : 1->1 conversions
- Translation 2nd Step : Opticks/GGeo Instancing : "Factorized" Geometry
- Ray Intersection with Transformed Object -> Geometry Instancing
- OpenGL Mesh Instancing ; OptiX Ray Traced Instancing
- Opticks Solids : CSG, Constructive Solid Geometry
- G4VSolid -> CUDA Intersect Functions for ~10 Primitives
- G4Boolean -> CUDA/OptiX Intersection Program Implementing CSG
- (CSG details relegated to "Extras")
- Opticks Material/Surface Properties : Boundary Texture
- Opticks vs Geant4 : Extrapolated G4 times compared to Opticks with RTX ON/OFF
- Overview + Links
JUNO Optical Photon Simulation Problem...
NVIDIA Marbles At Night RTX Demo
NVIDIA Marbles At Night RTX Demo 2
Ampere : 2nd Generation RTX
- NVIDIA:
- "...triple double over Turing..."
- Samsung 8nm (from TSMC 12nm)
- NVIDIA GeForce RTX 3090
- 10,496 CUDA Cores, 28GB VRAM
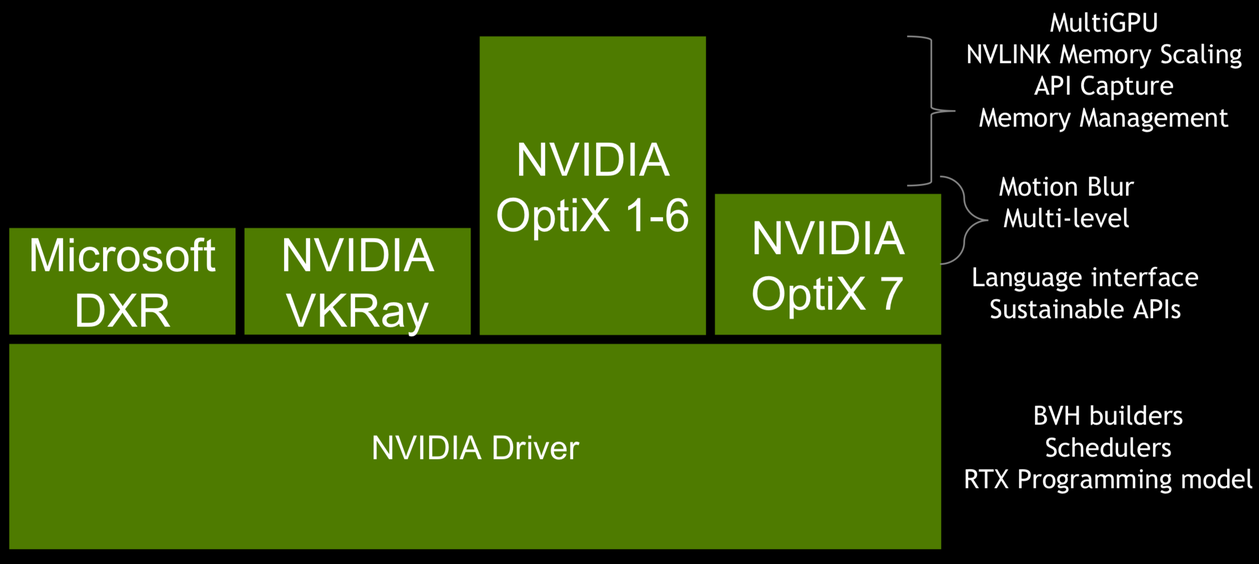
GPU Ray Tracing (RT) APIs Converging
Three Similar Interfaces over same RTX tech:
NVIDIA OptiX (Linux, Windows) [2009]
- CUDA header only access to Driver functionality
Vulkan RT (Linux, Windows) [final spec 2020]
- cross-vendor cross-platform RT
Microsoft DXR : DirectX 12 Ray Tracing (Windows) [2018]
- enhancing visual quality of realtime games
Metal Ray Tracing API (macOS) [introduced 2020[1]]
- Very different Integrated GPU : Apple Silicon M1 GPU
- BUT: similar API
[1] https://developer.apple.com/videos/play/wwdc2020/10012/
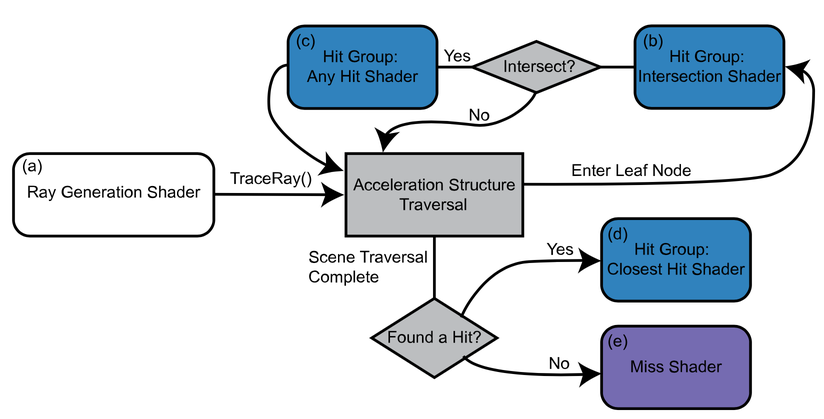
RTX Execution Pipeline : Common to DirectX RT, Vulkan NV RT, OptiX
Acceleration Structure (AS) traversal is central to pipeline performance
RG : Ray Generation
IS : Intersect
CH : Closest Hit
AH : Any Hit
MS : Miss
GPU Opticks
- RG
Cerenkov
Scintillation
"bounce" loop
- IS
- primitives, CSG
- CH
- IS->RG
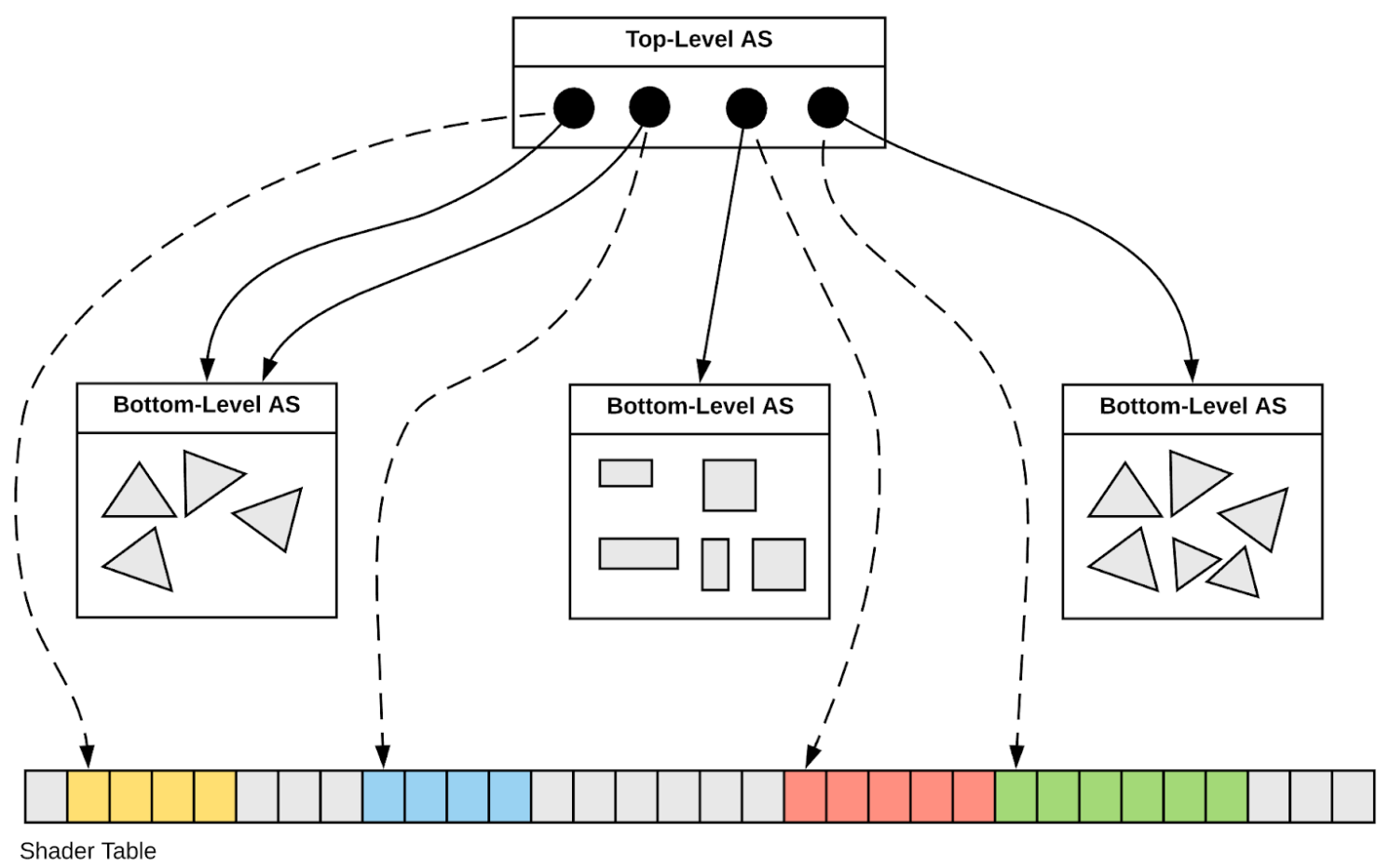
Spatial Index Acceleration Structure
Geant4OpticksWorkflow
NPY Serialization : Fundamental to Opticks Geometry Model
- Separate address space -> cudaMemcpy
- upload/download : host(CPU)<->device(GPU)
- Serialize everything -> Arrays
- Thread order undefined -> Arrays
- (each CUDA thread "owns" slots in the array)
Array-oriented : separate data from compute
- inherent serialization + simplicity
- avoid object serialization/de-serialization
- scales well to millions of element systems
Opticks/NPY pkg : Array Interface Using glm::mat4 glm::vec4
Opticks/GGeo classes implemented with NPY arrays
- all geometry objects persistable -> geocache
- some can be concatenated : GMesh, GParts
- No dependency on Geant4
[1] http://www.numpy.org/neps/nep-0001-npy-format.html
Translation 1st Step : Geant4 -> Opticks/GGeo : 1->1 conversions
Structural volumes : G4PVPlacement ->
- GVolume
- JUNO: tree of ~300,000 GVolume
Solid shapes : G4VSolid ->
- GMesh (collected into GMeshLib)
arrays: vertices, indices
ref to NCSG
- NCSG
- tree of NNode (CSG constituents)
Material/surface properties as function of wavelength
- G4Material -> GMaterial
- G4Logical(Border/Skin)Surface -> GSurface
- adopts standard wavelength domain
- collected into GMaterialLib GSurfaceLib
Translation steered by X4 package
https://bitbucket.org/simoncblyth/opticks/src/master/extg4/X4PhysicalVolume.hh
Translation 2nd Step : Opticks/GGeo Instancing : "Factorizes" Geometry
- Structural volumes vs solid shapes
distinction for convenience only, distinction is movable
JUNO: ~300,000 GVolume : mostly small repeated groups (PMTs)
GGeo/GInstancer
- GVolume progeny digest : shapes+transforms -> subtree ident.
- find repeated digests, disqualifying repeats inside others
- label all nodes with repeat index, non-repeated remainder : 0
For each repeat+remainder create GMergedMesh:
- collecting transforms, identity -> instance arrays
- merged volumes+solids
- GMesh: concatenated arrays: triangles, indices
- GParts: concatenated arrays: CSG nodes + transforms
- transforms applied -> gets into instance frame
- Consolidation : structural volumes -> compound solid
GMergedMesh -> IAS+GAS
- OptiX6 : ~10(IAS + GAS) OptiX7 Aim: 1 IAS + ~10 GAS
https://bitbucket.org/simoncblyth/opticks/src/master/ggeo/GInstancer.hh
OpenGL Instancing 2
OptiX Instancing
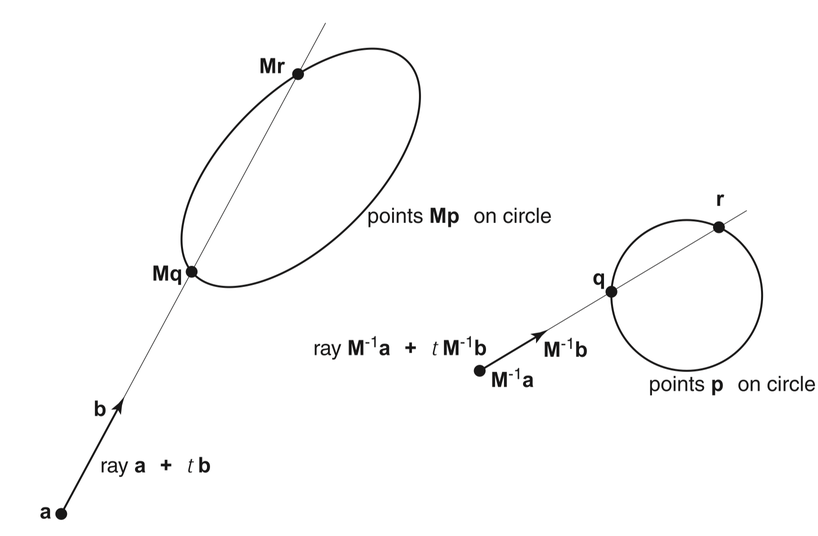
G4VSolid -> CUDA Intersect Functions for ~10 Primitives
- 3D parametric ray : ray(x,y,z;t) = rayOrigin + t * rayDirection
- implicit equation of primitive : f(x,y,z) = 0
- -> polynomial in t , roots: t > t_min -> intersection positions + surface normals
intersect_analytic.cu : for all shapes/concatenated-shapes/primitives
OptiXRap/cu/intersect_analytic.cu
- concatenated shapes, called for each primIdx
425 RT_PROGRAM void intersect(int primIdx)
426 {
427 const Prim& prim = primBuffer[primIdx];
428
429 unsigned partOffset = prim.partOffset() ;
430 unsigned numParts = prim.numParts() ;
431 unsigned primFlag = prim.primFlag() ;
432
433 if(primFlag == CSG_FLAGNODETREE)
434 {
435 evaluative_csg( prim, primIdx );
436 }
474 }
229 RT_PROGRAM void bounds (int primIdx, float result[6])
230 {
251 optix::Aabb* aabb = (optix::Aabb*)result;
252 *aabb = optix::Aabb();
253
254 uint4 identity =
identityBuffer[instance_index*primitive_count+primIdx] ;
...
271 const Prim& prim = primBuffer[primIdx];
...
294 if(primFlag == CSG_FLAGNODETREE || primFlag == CSG_FLAGINVISIBLE )
295 {
301 csg_bounds_prim(primIdx, prim, aabb);
318 }
385 }
https://bitbucket.org/simoncblyth/opticks/src/master/optixrap/cu/intersect_analytic.cu
G4Boolean -> CUDA/OptiX Intersection Program Implementing CSG
Complete Binary Tree, pick between pairs of nearest intersects:
| UNION tA < tB |
Enter B |
Exit B |
Miss B |
|---|
| Enter A |
ReturnA |
LoopA |
ReturnA |
| Exit A |
ReturnA |
ReturnB |
ReturnA |
| Miss A |
ReturnB |
ReturnB |
ReturnMiss |
- Nearest hit intersect algorithm [1] avoids state
- sometimes Loop : advance t_min , re-intersect both
- classification shows if inside/outside
- Evaluative [2] implementation emulates recursion:
- recursion not allowed in OptiX intersect programs
- bit twiddle traversal of complete binary tree
- stacks of postorder slices and intersects
- Identical geometry to Geant4
- solving the same polynomials
- near perfect intersection match
- [1] Ray Tracing CSG Objects Using Single Hit Intersections, Andrew Kensler (2006)
- with corrections by author of XRT Raytracer http://xrt.wikidot.com/doc:csg
- [2] https://bitbucket.org/simoncblyth/opticks/src/tip/optixrap/cu/csg_intersect_boolean.h
- Similar to binary expression tree evaluation using postorder traverse.
Opticks : Translates G4 Geometry to GPU, Without Approximation
G4 Structure Tree -> Instance+Global Arrays -> OptiX
Group structure into repeated instances + global remainder:
- auto-identify repeated geometry with "progeny digests"
- JUNO : 5 distinct instances + 1 global
- instance transforms used in OptiX/OpenGL geometry
instancing -> huge memory savings for JUNO PMTs
j1808_top_rtx
j1808_top_ogl
Opticks Analytic Daya Bay Near Site, GPU Raytrace (3)
Opticks Analytic Daya Bay Near Site, GPU Raytrace (1)
scan-pf-1_Opticks_vs_Geant4 2
| JUNO analytic, 400M photons from center |
Speedup |
|---|
| Geant4 Extrap. |
95,600 s (26 hrs) |
|
| Opticks RTX ON (i) |
58 s |
1650x |
Useful Speedup > 1500x : But Why Not Giga Rays/s ? (1 Photon ~10 Rays)
- NVIDIA claim : 10 Giga Rays/s with RT Core
- -> 1 Billion photons per second
- RT cores : built-in triangle intersect + 1-level of instancing
- flatten scene model to avoid SM<->RT roundtrips ?
OptiX Performance Tools and Tricks, David Hart, NVIDIA
https://developer.nvidia.com/siggraph/2019/video/sig915-vid
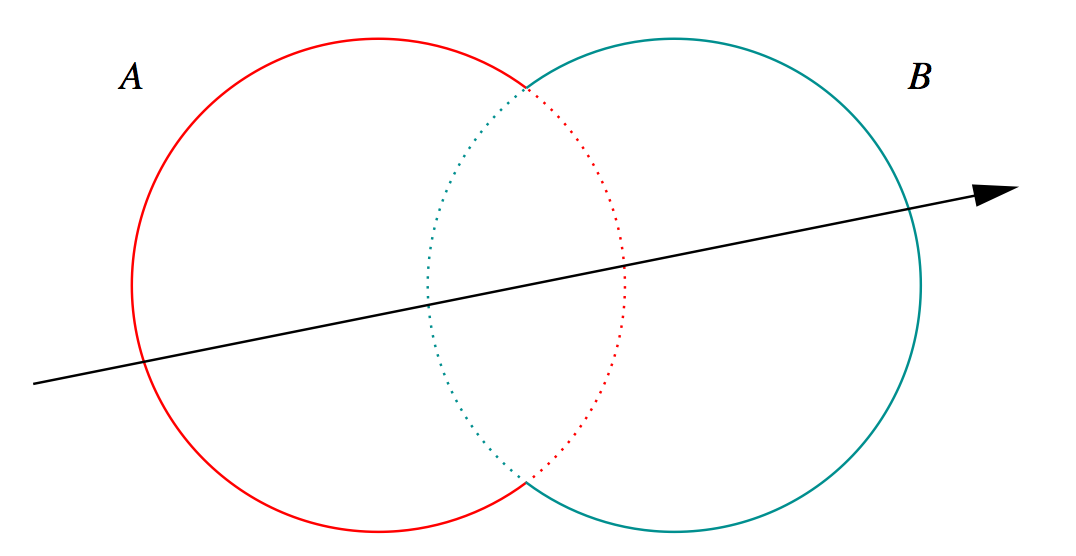
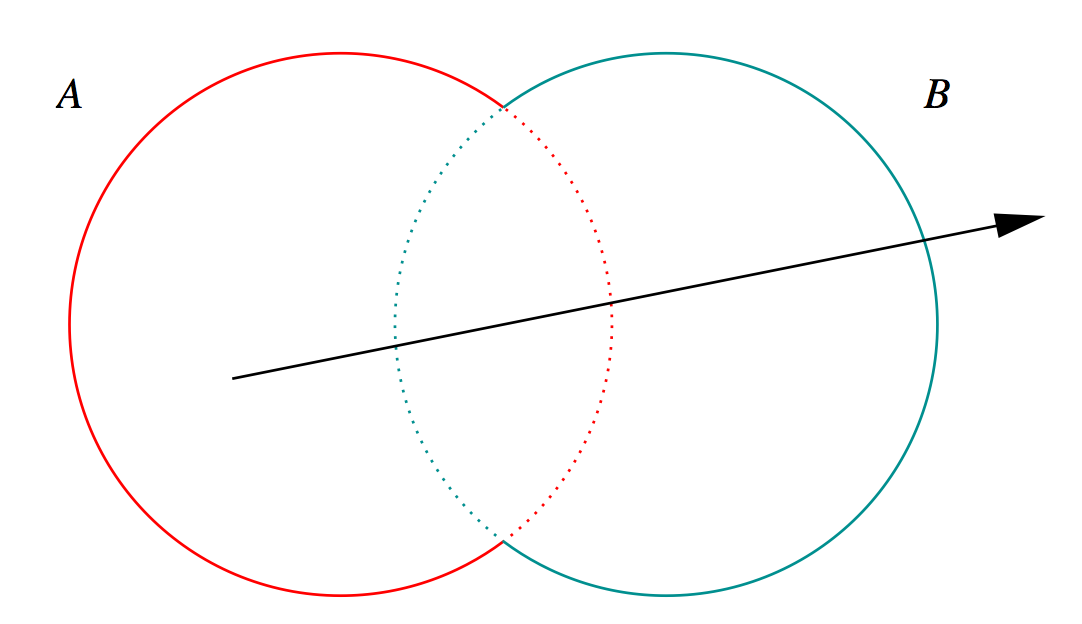
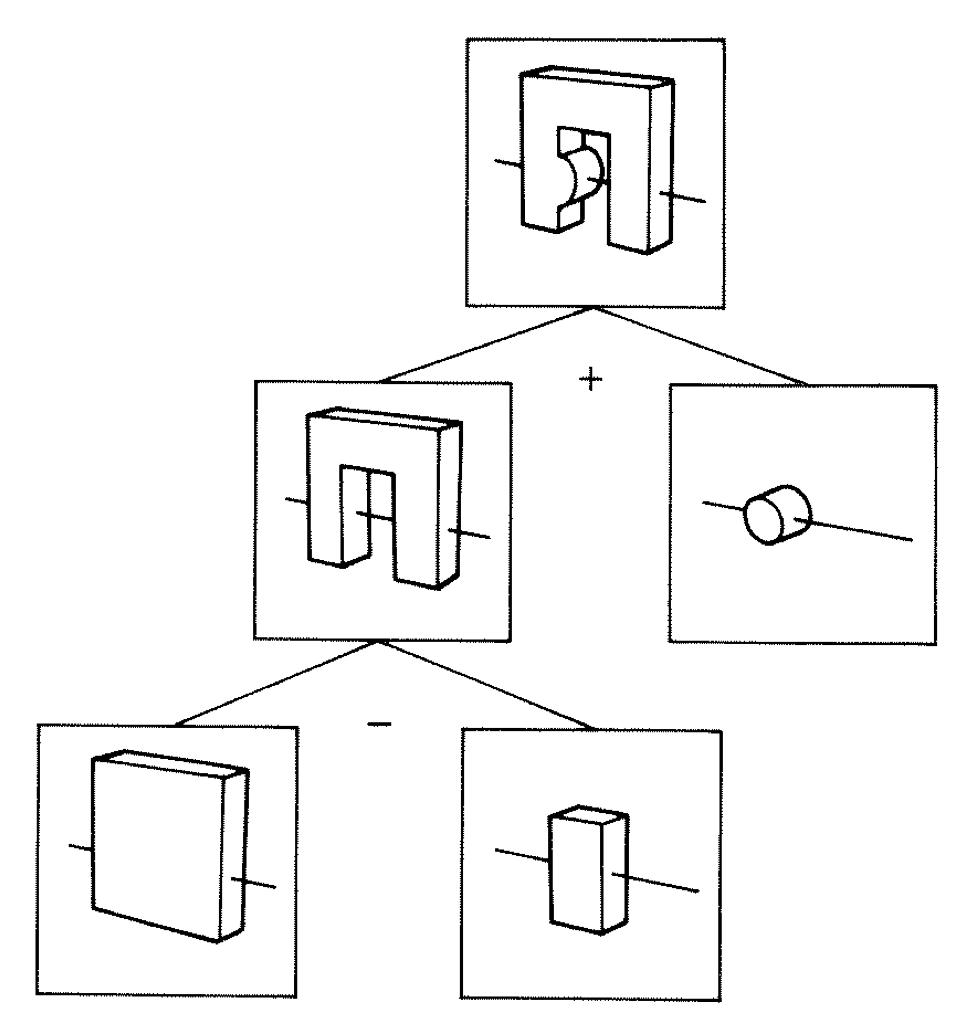
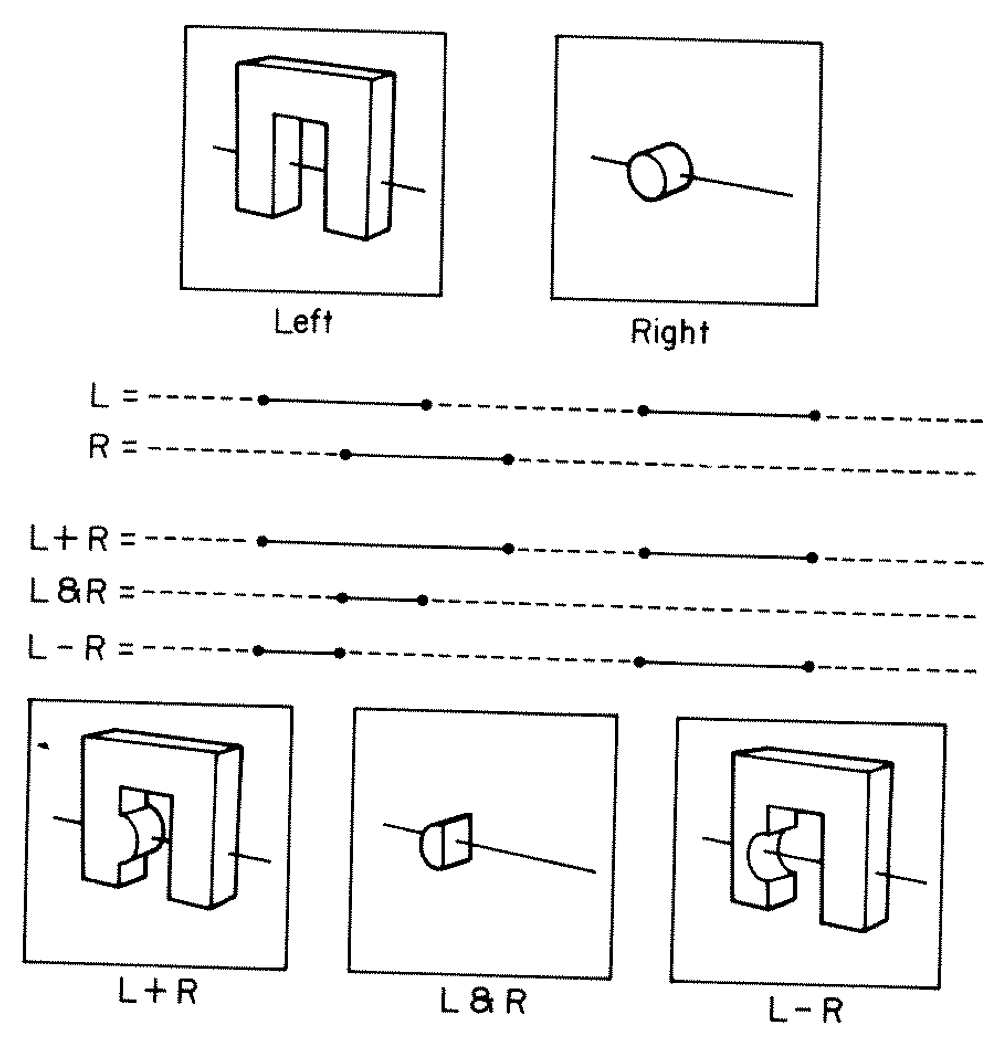
Constructive Solid Geometry (CSG) : Shapes defined "by construction"
Simple by construction definition, implicit geometry.
- A, B implicit primitive solids
- A + B : union (OR)
- A * B : intersection (AND)
- A - B : difference (AND NOT)
- !B : complement (NOT) (inside <-> outside)
CSG expressions
- non-unique: A - B == A * !B
- represented by binary tree, primitives at leaves
3D Parametric Ray : ray(t) = r0 + t rDir
Ray Geometry Intersection
- primitive : find t roots of implicit eqn
- composite : pick primitive intersect, depending on CSG tree
How to pick exactly ?
CSG : Which primitive intersect to pick ?
Classical Roth diagram approach
- find all ray/primitive intersects
- recursively combine inside intervals using CSG operator
- works from leaves upwards
Computational requirements:
- find all intersects, store them, order them
- recursive traverse
BUT : High performance on GPU requires:
- massive parallelism -> more the merrier
- low register usage -> keep it simple
- small stack size -> avoid recursion
Classical approach not appropriate on GPU
CSG Complete Binary Tree Serialization -> simplifies GPU side
Geant4 solid -> CSG binary tree (leaf primitives, non-leaf operators, 4x4 transforms on any node)
Serialize to complete binary tree buffer:
- no need to deserialize, no child/parent pointers
- bit twiddling navigation avoids recursion
- simple approach profits from small size of binary trees
- BUT: very inefficient when unbalanced
Height 3 complete binary tree with level order indices:
depth elevation
1 0 3
10 11 1 2
100 101 110 111 2 1
1000 1001 1010 1011 1100 1101 1110 1111 3 0
postorder_next(i,elevation) = i & 1 ? i >> 1 : (i << elevation) + (1 << elevation) ; // from pattern of bits
Postorder tree traverse visits all nodes, starting from leftmost, such that children
are visited prior to their parents.
Evaluative CSG intersection Pseudocode : recursion emulated
fullTree = PACK( 1 << height, 1 >> 1 ) // leftmost, parent_of_root(=0)
tranche.push(fullTree, ray.tmin)
while (!tranche.empty) // stack of begin/end indices
{
begin, end, tmin <- tranche.pop ; node <- begin ;
while( node != end ) // over tranche of postorder traversal
{
elevation = height - TREE_DEPTH(node) ;
if(is_primitive(node)){ isect <- intersect_primitive(node, tmin) ; csg.push(isect) }
else{
i_left, i_right = csg.pop, csg.pop // csg stack of intersect normals, t
l_state = CLASSIFY(i_left, ray.direction, tmin)
r_state = CLASSIFY(i_right, ray.direction, tmin)
action = LUT(operator(node), leftIsCloser)(l_state, r_state)
if( action is ReturnLeft/Right) csg.push(i_left or i_right)
else if( action is LoopLeft/Right)
{
left = 2*node ; right = 2*node + 1 ;
endTranche = PACK( node, end );
leftTranche = PACK( left << (elevation-1), right << (elevation-1) )
rightTranche = PACK( right << (elevation-1), node )
loopTranche = action ? leftTranche : rightTranche
tranche.push(endTranche, tmin)
tranche.push(loopTranche, tminAdvanced ) // subtree re-traversal with changed tmin
break ; // to next tranche
}
}
node <- postorder_next(node, elevation) // bit twiddling postorder
}
}
isect = csg.pop(); // winning intersect
https://bitbucket.org/simoncblyth/opticks/src/tip/optixrap/cu/csg_intersect_boolean.h
CSG Deep Tree : JUNO "fastener"

CSG Deep Tree : height 11 before balancing, too deep for GPU raytrace
NTreeAnalyse height 11 count 25 ( un : union, cy : cylinder, di : difference )
un
un di
un cy cy cy
un cy
un cy
un cy
un cy
un cy
un cy
un cy
di cy
cy cy
CSG trees are non-unique
- many possible expressions of same shape
- some much more efficiently represented as complete binary trees
CSG Deep Tree : Positivize tree using De Morgan's laws
1st step to allow balancing : Positivize : remove CSG difference di operators
... ...
un cy
un cy
un cy
un cy
un cy
di cy
cy cy
... ...
un cy
un cy
un cy
un cy
un cy
in cy
cy !cy
CSG Deep Tree : height 4 after balancing, OK for GPU raytrace
NTreeAnalyse height 4 count 25
un
un un
un un un in
un un un un cy in cy !cy
cy cy cy cy cy cy cy cy cy !cy
un : union, in : intersect, cy : cylinder, !cy : complemented cylinder
Balancing positive tree:
- classify tree operators and their placement
- mono-operator trees can easily be rearranged as union un and intersection in operators are commutative
- mono-operator above bileaf level can also easily be rearranged as the bileaf can be split off and combined
- create complete binary tree of appropriate size filled with placeholders
- populate the tree replacing placeholders
- prune (pull primitives up to avoid placeholder pairings)
Not a general balancer : but succeeds with all CSG solid trees from Daya Bay and JUNO so far
https://bitbucket.org/simoncblyth/opticks/src/default/npy/NTreeBalance.cpp
CSG Examples
Torus : much more difficult/expensive than other primitives
3D parametric ray : ray(x,y,z;t) = rayOrigin + t * rayDirection
- ray-torus intersection -> solve quartic polynomial in t
- A t^4 + B t^3 + C t^2 + D t + E = 0
High order equation
- very large difference between coefficients
- varying ray -> wide range of very coefficients
- numerically problematic, requires double precision
- several mathematical approaches used, work in progress
Best Solution : replace torus
- eg model PMT neck with hyperboloid, not cylinder-torus
Torus : different artifacts as change implementation/params/viewpoint
- Only use Torus when there is no alternative
- especially avoid CSG combinations with Torus